
We try to analyse bibliographical data using big data technology (flink, elasticsearch, metafacture).
Here a first sketch of what we're aiming at:
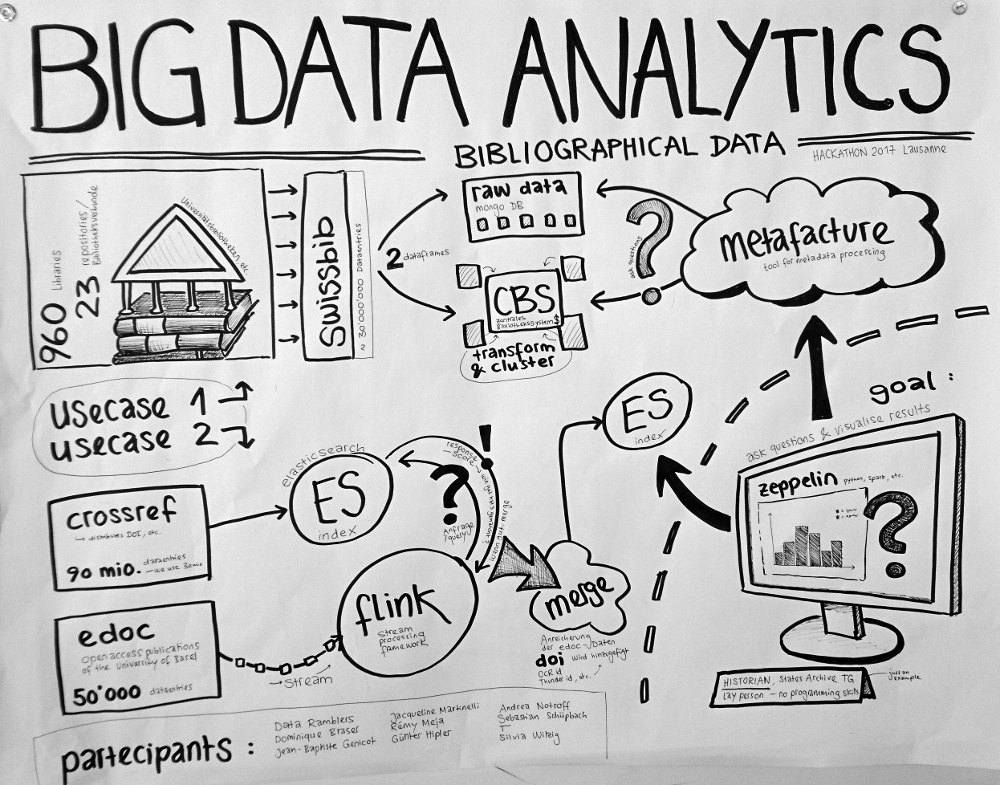
Datasets
We use bibliographical metadata:
Swissbib bibliographical data https://www.swissbib.ch/
-
Catalog of all the Swiss University Libraries, the Swiss National Library, etc.
-
960 Libraries / 23 repositories (Bibliotheksverbunde)
-
ca. 30 Mio records
-
MARC21 XML Format
-
→ raw data stored in Mongo DB
-
→ transformed and clustered data stored in CBS (central library system)
-
Institutional Repository der Universität Basel (Dokumentenserver, Open Access Publications)
-
ca. 50'000 records
-
JSON File
crossref https://www.crossref.org/
-
Digital Object Identifier (DOI) Registration Agency
-
ca. 90 Mio records (we only use 30 Mio)
-
JSON scraped from API
Use Cases
Swissbib
Librarian:
-
For prioritizing which of our holdings should be digitized most urgently, I want to know which of our holdings are nowhere else to be found.
-
We would like to have a list of all the DVDs in swissbib.
-
What is special about the holdings of some library/institution? Profile?
Data analyst:
- I want to get to know better my data. And be faster.
→ e.g. I want to know which records don't have any entry for ‚year of publication'. I want to analyze, if these records should be sent through the merging process of CBS. Therefore I also want to know, if these records contain other ‚relevant' fields, defined by CBS (e.g. ISBN, etc.). To analyze the results, a visualization tool might be useful.
edoc
Goal: Enrichment. I want to add missing identifiers (e.g. DOIs, ORCID, funder IDs) to the edoc dataset.
→ Match the two datasets by author and title
→ Quality of the matches? (score)
Tools
elasticsearch https://www.elastic.co/de/
JAVA based search engine, results exported in JSON
Flink https://flink.apache.org/
open-source stream processing framework
Metafacture https://culturegraph.github.io/, https://github.com/dataramblers/hackathon17/wiki#metafacture
Tool suite for metadata-processing and transformation
Zeppelin https://zeppelin.apache.org/
Visualisation of the results
How to get there
Usecase 1: Swissbib
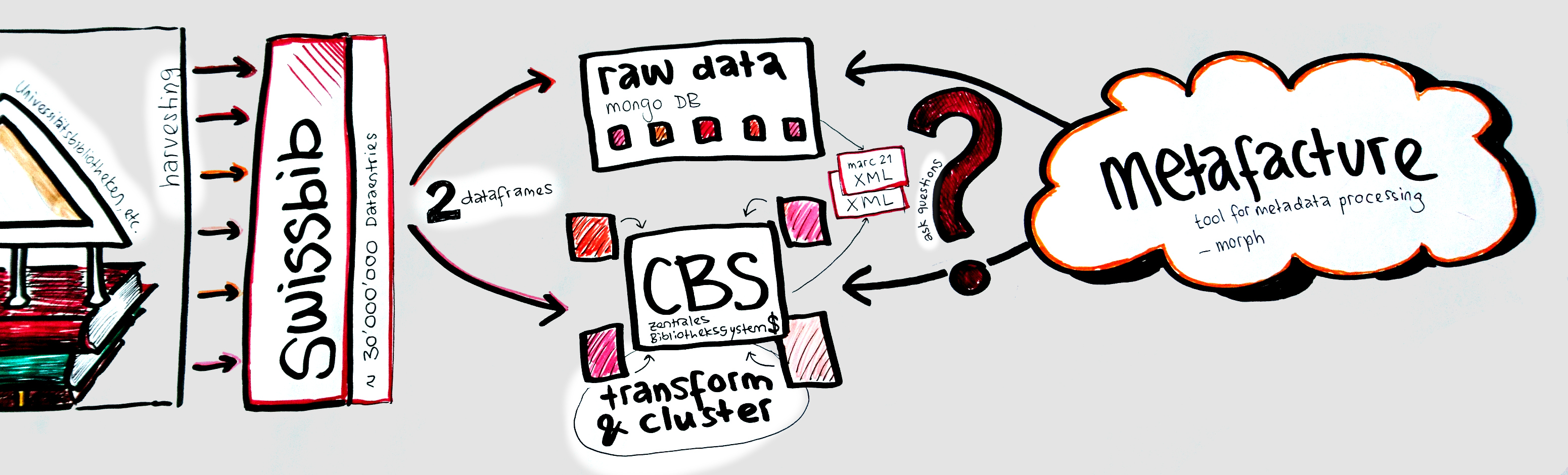
Usecase 2: edoc
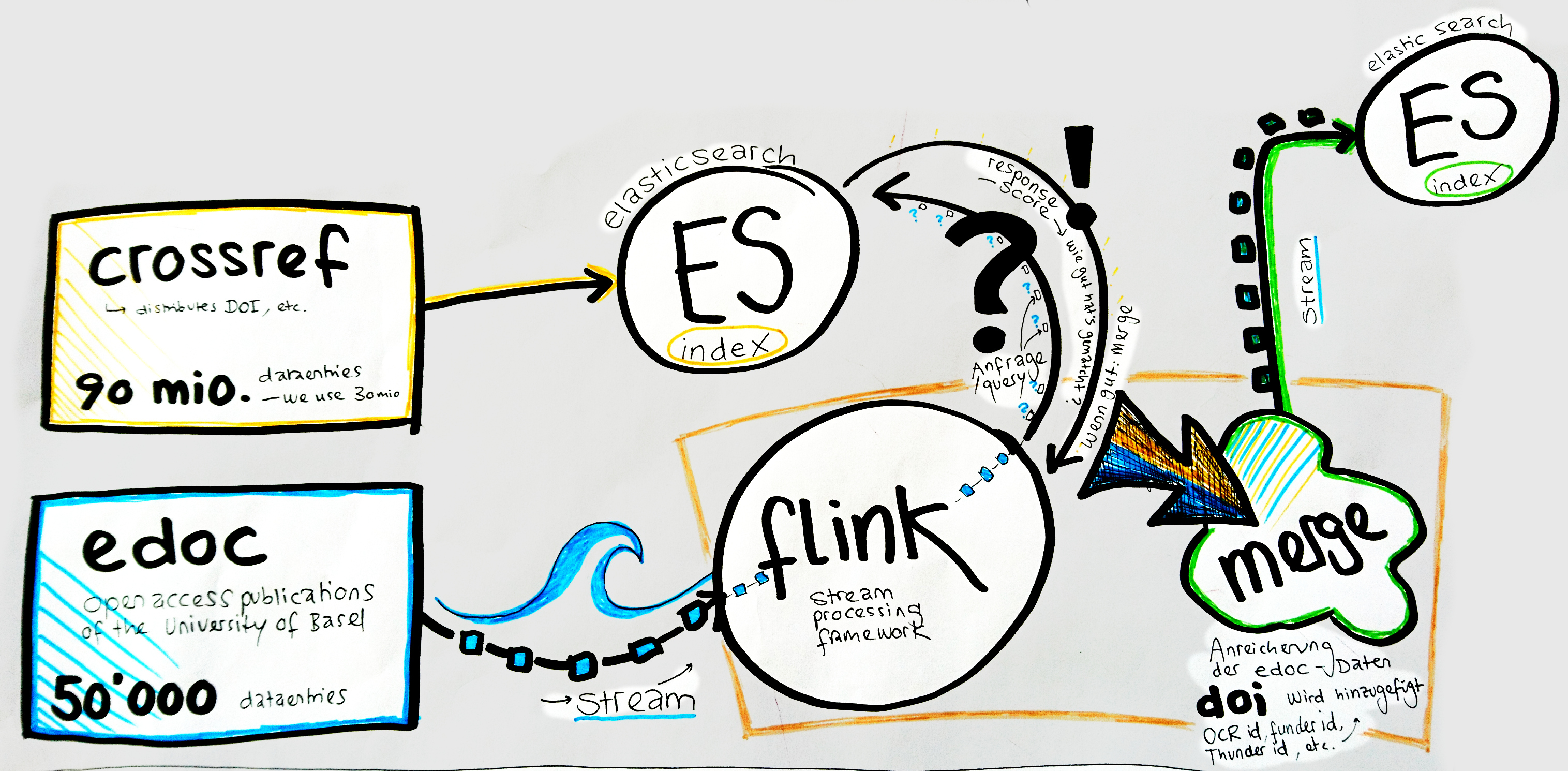
Links
Data Ramblers Project Wiki https://github.com/dataramblers/hackathon17/wiki
Team
- Data Ramblers https://github.com/dataramblers
- Dominique Blaser
- Jean-Baptiste Genicot
- Günter Hipler
- Jacqueline Martinelli
- Rémy Mej
- Andrea Notroff
- Sebastian Schüpbach
- T
- Silvia Witzig
hackathon17
Files and notes about the Swiss Open Cultural Data Hackathon 2017. For information about the data, use cases, tools, etc, see the Wiki: https://github.com/dataramblers/hackathon17/wiki
Requirements
Elasticsearch cluster
-
see https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html (especially paragraph on production mode)
-
Elasticsearch requires increased virtual memory. See: https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html
Docker
- Docker CE, most recent version
- recommended: 17.06
- see also hints.md
Docker Compose
- most recent version
- see also hints.md
Installation notes
The technical environment runs in Docker containers. This enables everyone to run the infrastructure locally on their computers provided that Docker and Docker Compose are installed.
How to install Docker and Docker Compose
The package sources of many (Linux-) distributions do not contain the most recent version of Docker, and do not contain Docker Compose at all. You must most likely install them manually.
- Install Docker CE, preferably 17.06.
- https://docs.docker.com/engine/installation/
- Verify correct installation:
sudo docker run hello-world
- Install Docker-Compose.
- https://docs.docker.com/compose/install/
- Check installed version:
docker-compose --version
- Clone this repository.
git clone git@github.com:dataramblers/hackathon17.git
- Increase your virtual memory: https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html
How to run the technical environment in Docker (for Linux users)
Use sudo for Docker commands.
- Make sure you have sufficient virtual memory:
sysctl vm.max_map_countmust output at least262144.
- To increase the limits for one session:
sudo sysctl -w vm.max_map_count=262144 - To increase the limits permanently:
- Create a new
.conffile in/etc/sysctl.d/(e.g.10-vm-max-map-count.conf, the prefix number just indicating the order in which the files are parsed) - Add the line
vm.max_map_count=262144and save the file - Reread values for sysctl:
sudo sysctl -p --system
- Create a new
cdto yourhackathon17directory.docker-compose up-> Docker loads the images and initializes the containers- Access to the running applications:
- Elasticsearch HTTP:
localhost:9200 - Elasticsearch TCP:
localhost:9300 - Zeppelin instance:
localhost:8080 - Flink RPC:
localhost:6123 - Dashboard of the Flink cluster:
localhost:8081
- If you want to stop and exit the docker containers:
docker-compose down(in separate terminal) orCtrl-c(in same terminal)
Open Cultural Data Hackathon 2017
Next project