
Report
💡 Active projects and challenges as of 21.07.2026 21:54.
Hide text CSV Data Package Print
Artify
display data of museumobjects in a innovative and explorative way
Explore the collection in a new, interessting way
You have to find objects, which have similar metadata and try to match them. The displayed objects are (semi-)randomly selected from a dataset (eg. from SNM). From the metadata of the starting object, the app will search for three other objects:
-
One which matches in 2+ metadata tags
-
One which matches in 1 metadata tag
-
One which is completly random.
If you choose the right one, the app will display three new objects accordingly to the way explained above.
Tags used from the datasets:
-
OBJEKT Klassifikation (x)
-
OBJEKT Webtext
-
OBJEKT Datierung (x)
-
OBJEKT → Herstellung (x)
-
OBJEKT → Herkunft (x)
(x) = used for matching
To Do
-
Datasets are too divers; in some cases there is no match. Datasets need to be prepared.
-
The tag "Klassifikation" is too specific
-
The tags "Herstellung" and "Herkunft" are often empty or not consistent.
-
The gaming aspect needs to be implemented
Use case
There are various cases, where the app could be used. It mainly depends on the datasets you use:
-
Explore hidden objects of a museum collection
-
Train students to identify art periods
-
Find connections between museums, which are not obvious (e.g. art and historical objects)
Data
Democase:
SNM https://opendata.swiss/en/organization/schweizerisches-nationalmuseum-snm
--> Build with two sets: Technologie und Brauchtum / Kutschen & Schlitten & Fahrzeuge
Links
https://github.com/zack17/ocdh2018
Tech. Demo: https://zack17.github.io/ocdh2018/
Design Demo (not functional): https://tempestas.ch/artify/
Team
- Micha Reiser
- Jacqueline Martinelli
- Anastasiya Korotkova
- Dominic Studer
- Yaw Lam
ocdh2018
ARTIFY
The goal of this project is to display different data of museumobjects in a innovative way.
Source
Datasource of the project is open data from the Landesmuseum Zürich. https://opendata.swiss/en/organization/schweizerisches-nationalmuseum-snm
Build during the 4th Swiss Open Cultural Data Hackathon. (http://make.opendata.ch/wiki/event:2018-10)
Art on Paper Gallery
The gallery app for browsing drawings, etchings, engravings, woodcuts and other art on the paper. It uses public dataset of Graphische Sammlung from ETH Zurich
We develop a gallery app for browsing art works on paper. For the prototype we use a dataset sample delivered from the Collection Online of the Graphische Sammlung ETH Zurich. In our app the user can find the digital images of the prints and drawings, gets metadata information about the different techniques and other details. The app invites the user to browse from one art work to the other, following different paths such as the same technique, the same artist, the same subject and so on.
Challenge
To use a Collection Online properly the user needs previous knowledge. Many people just love art and are interested but no experts.
User
Especially this group of people is invited to explore our large collection in an interactive journey.
Goals
-
The Art on Paper Gallery App enables the user to jump from one artwork to another in an associative way. It offers suggestions following different categories, such as the artist, technique, etc.
-
It allows social interaction with the possibility to like, share and comment an artwork
-
Artworks can be arranged according to relevance, number of clicks etc.
-
This again allows Collections or Museums to evaluate the user interests and trends
Code
The code is available at the following link: https://github.com/DominikStefancik/Art-on-Paper-Gallery-App.
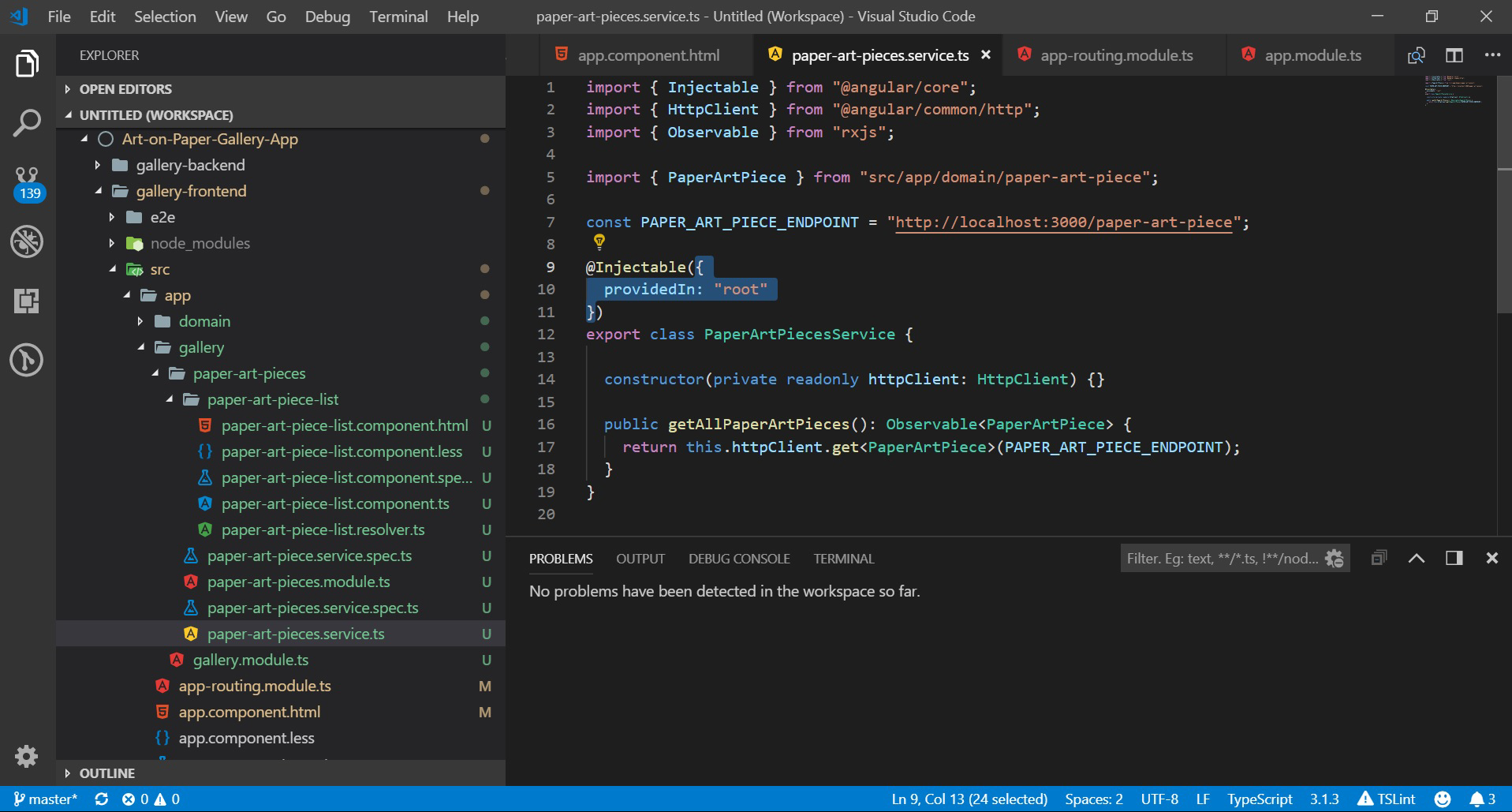
Example of a possible Design

Data
- Graphische Sammlung ETH Zurich, Collection Online, sample dataset with focus on different techniques of printmaking and drawing
Team
- Dominik Štefančik, Software Engineer
- Graphische Sammlung ETH Zurich, Susanne Pollack, Ann-Kathrin Seyffer
Art-on-Paper-Gallery-App
The gallery app for browsing drawings, etchings, engravings, woodcuts and other art on the paper. It uses public dataset of Graphische Sammlung from ETH Zurich
Ask the Artist
The project idea is to create a voice assistance with the identity of an artist. In our case, we created a demo of the famous Swiss painter Ferdinand Hodler. That is to say, the voice assistance is nor Siri nor Alexa. Instead, it is an avatar of Ferdinand Hodler who can answer your questions about his art and his life.
You can directly interact with the program by talking, as what you would do normally in your daily life. You can ask it all kinds of questions about Ferdinand Hodler, e.g.:
-
When did you start painting?
-
Who taught you painting?
-
Can you show me some of your paintings?
-
Where can I find an exhibition with your artworks?
By talking to the digital image of the artist directly, we aim to bring the art closer to people's daily life, in a direct, intuitive and hopefully interesting way.
As you know, museum audiences need to keep quiet which is not so friendly to children. Also, for people with special needs, like the visually dispaired, and people without professional knowledge about art, it is not easy for them to enjoy the museum visit. To make art accessible to more people, a voice assistance can help with solving those barriers.
If you asked the difference between our product with Amazon's Alexa or Apple's Siri, there are two major points:
-
The user can interact with the artist in a direct way: talking to each other. In other applications, the communication happened by Alexa or Siri to deliver the message as the 3rd party channel. In our case, users can have immersive and better user experienceand they will feel like if they were talking to an artist friend, not an application.
-
The other difference is that the answers to the questions are preset. The essence of how Alexa or Siri works is that they search the question asked by users online and read the returned search results out. In that case, we cannot make sure that the answer is correct and/or suitable. However, in our case, all the answers are coming from reliable data sets of museum and other research institutions, and have been verified and proofread by the art experts. Thus, we can proudly say, the answers from us are reliable and correct. People can use it as a tool to educate children or as visiting assistance in the exhibition.



Video demo:
Data
-
List and link your actual and ideal data sources.
-
Kunsthaus Zürich
⭐️ List of all Exhibitions at Kunsthaus Zürich
- SIK-ISEA
⭐️ Artist data from the SIKART Lexicon on art in Switzerland
- Swiss National Museum
⭐️ Representative sample from the Paintings & Sculptures Collection (images and metadata)
- Wikimedia Switzerland
Team
- Angelica
- Barbara
- Anlin (lianganlin@foxmail.com)
Dog Name Creativity
Survey of New York City
We started this project to see if art and cultural institutions in the environment have an impact on the creativity of dognames. This was not possible with the date from Zurich because the name-dataset does not contain information about the location and the dataset about the owners does not include the dognames. We choose to stick with our idea but used a different dataset: NYC Dog Licensing Dataset.
The creativity of a name is measured by the frequency of each letter in the English language and gets +/- points according to the amount of dogs with the same name. The data for the cultural environment comes from Wikidata.
After some data-cleaning with OpenRefine and failed attempts with OpenCalc we got the following code:
import string
import pandas as pd
numbers_ = {"e":1,"t":2,"a":3,"o":4,"n":5,"i":6,"s":7,"h":8,"r":9,"l":10,"d":11,"u":12,"c":13,"m":14,"w":15,"y":16,"f":17,"g":18,"p":19,"b":20,"v":21,"k":22,"j":23,"x":24,"q":25,"z":26}
name_list = []
def KreaWert(name_):
name_ = str(name_)
wert_ = 0
for letter in str.lower(name_):
temp_ = 0
if letter in string.ascii_lowercase :
temp_ += numbers_[letter]
wert_ += temp_
if name_ in H_:
wert_ = wert_* ((Hmax-H_[name_])/(Hmax-1)*5 + 0.2)
return round(wert_,1)
df = pd.read_csv("Vds3.csv", sep = ";")
df["AnimalName"] = df["AnimalName"].str.strip()
H_ = df["AnimalName"].value_counts()
Hmax = max(H_)
Hmin = min(H_)
df["KreaWert"] = df["AnimalName"].map(KreaWert)
df.to_csv("namen2.csv")
dftemp = df[["AnimalName", "KreaWert"]].drop_duplicates().set_index("AnimalName")
dftemp.to_csv("dftemp.csv")
df3 = pd.DataFrame()
df3["amount"] = H_
df3 = df3.join(dftemp, how="outer")
df3.to_csv("data3.csv")
df1 = round(df.groupby("Borough").mean(),2)
df1.to_csv("data1.csv")
df2 = round(df.groupby(["Borough","AnimalGender"]).mean(),2)
df2.to_csv("data2.csv")
Visualisations were made with D3: https://d3js.org/
Data
Hundedaten der Stadt Zürich:
-
https://opendata.swiss/de/dataset/hundenamen-aus-dem-hundebestand-der-stadt-zurich
-
https://opendata.swiss/de/dataset/hundebestand-der-stadt-zurich
NYC Dog Licensing Dataset:
Team
- Birk Weiberg
- Dominik Sievi
Find Me an Exhibit
Are you ready to take up the challenge? Film categories of objects in the exhibition "History of Switzerland" running against the clock.
The app displays one of several categories of exhibits that can be found in the exhibition (like "cloths", "paintings" or "clocks"). Your job is to find a matching exhibit as quick as possible. You don't have much time, so hurry up!
Best played on portable devices. 
The frontend of the app is based on the game "Emoji Scavenger Hunt", the model is built with TensorFlow.js fed with a lot of images kindly provided by the National Museum Zurich. The app is in pre-alpha stage.
Data
Team
- Some data ramblers
Letterjongg
Adaptation of the Mahjong Game
In 1981 Brodie Lockard, a Stanford University student, developed a computer game just two years after a serious gymnastics accident had almost taken his life and left him paralyzed from the neck down. Unable to use his hands to type on a keyboard, Lockard made a special request during his long recovery in hospital: He asked for a PLATO terminal. PLATO (Programmed Logic for Automatic Teaching Operations) was the first generalized computer-assisted instruction system designed and built by the University of Illinois.
The computer game Lockard started coding on his PLATO terminal was a puzzle game displaying Chinese «Mah-Jongg» tiles, pieces used for the Chinese game that had become increasingly popular in the United States. Lockard accordingly called his game «Mah-Jongg solitaire». In 1986 Activision released the game under the name of «Shanghai» (see screenshot), and when Microsoft decided to add the game to their Windows Entertainment Pack für Win 3.x in 1990 (named «Taipei» for legal reasons) Mah-Jongg Solitaire became one of the world's most popular computer games ever.
Typography
«Letterjongg» aims at translating the ancient far-east Mah-Jongg imagery into late medieval typography. 570 years ago the invention of the modern printing technology by Johannes Gutenberg in Germany (and, two decades later, by William Caxton in England) was massively disruptive. Books, carefully bound manuscripts written and copied by scribes in weeks, if not months, could all of a sudden be mass-produced in a breeze. The invention of moveable types as such, along with other basic book printing technologies, had a huge impact on science and society.
Yet, 15th century typographers were not only businessmen, they were artists as well. Early printing fonts reflect their artistic past. The design of 15th/16th century fonts is still influenced by their calligraphic predecessors. A new book, although produced by means of a new technology, was meant to be what it had been for centuries: a precious document, often decorated with magnificent illustrations. (Incunables -- books printed before 1500 -- often have a blank space in the upper left corner of a page so that illustrators could manually add artful initials after the printing process.)
Letterjongg comes with 144 typographic tiles (hence 36 tile faces). The letters have been taken and isolated from a high resolution scan (2,576 × 4,840 pixels, file size: 35.69 MB, MIME type: image/tiff) of Aldus Pius Manutius, Horatius Flaccus, Opera (font design by Francesco Griffo, Venice, 1501). «Letterjongg» has been slightly simplified. Nevertheless it is not easy to play as the games are set up at random (actually not every game can be finished) and the player's visual orientation is constrained by the sheer number and resemblance of the tiles.

Letterjongg, Screenshot
Technical
The game is coded in dynamic HTML (HTML 5, CSS 3, Javascript); no external frameworks or libraries were used.
Rules
Starting from the sides, or from the central tile at the top of the pile, remove tiles by clicking on two equal letters. If the tiles are identical, they will disappear, and your score will rise. Removeable tiles always must be free on their left or right side. If a tile sits between two tiles on the same level, it cannot be selected.
Version history
- 2018/10/26 v0.1: Basic game engine, prototype\
- 2018/10/27 v0.11: Moves counter, about\
- 2018/10/30 v0.2: Matches counter\
- 2018/11/06 v0.21: Animations
Data
-
Wikimedia Commons, Aldus Manutius, Horatius Flaccus, Opera, Venice, 1501
-
Europeana, Quincti Horatii Flacci Poemata omnia, 1629
Team
- Prof. Thomas Weibel, Thomas Weibel Multi & Media, University of Applied Sciences Chur/Bern University of the Arts
- Dr. des. Elias Kreyenbühl, University Library of Basel
Sex and Crime und Kneippenschlägereien in Early Modern Zurich
Minutes reported by pastor in Early Modern Zurich
Make the "Stillstandsprotokolle" searchable, georeferenced and browsable and display them on a map.
For more Info see our Github Repository
Access the documents: archives-quickaccess.ch/search/stazh/stpzh
Data
- Primary Data
- Secondary data
- Siedlungsverzeichnis des Kantons Zürich: http://www.web.statistik.zh.ch/cms_siedlungsverzeichnis/daten.php
Team
- Ernst Rosser, ernst.rosser@gmail.com
- Tobias Hodel, tobias.hodel@ji.zh.ch
- Barbara Leimgruber, Barbara.Leimgruber@ji.zh.ch
- Rebekka Plüss, Rebekka.Pluess@ji.zh.ch
- Ismail Prada, ismail.prada@gmail.com
- Matthias Mazenauer, matthias.mazenauer@statistik.ji.zh.ch
#glamhack2018
Sex and Crime und Kneipenschlägereien in der Frühen Neuzeit
Goal
Make the data ("Stillstandsprotokolle des 17. Jahrhunderts") better searchable and georeference it for visualization.
Team
- Ernst Rosser, ernst.rosser@gmail.com
- Barbara Leimgruber, Barbara.Leimgruber@ji.zh.ch
- Rebekka Plüss, Rebekka.Pluess@ji.zh.ch
- Ismail Prada, ismail.prada@gmail.com
- Matthias Mazenauer, matthias.mazenauer@statistik.ji.zh.ch
- Tobias Hodel, tobias.hodel@ji.zh.ch
Data sources:
-
Primary Data
-
Secondary data
Steps taken
- Create lookup for normalized strings (https://github.com/mmznr/Staatsarchiv-GLAMhack/blob/master/woerterStillstand_Result.tsv)
- Annotate named entities (normalization) -> places (also add BfS-data) -> persons (normalization to be used for auto-complete in search)
- Cluster words -> based on "Frequenztabelle Stillstandsprotokolle", see https://github.com/mmznr/Staatsarchiv-GLAMhack/blob/master/README.md#frequency-list-of-word-cluster -> to be used to refer to topic/concept
- Cluster documents -> to be used as keyword(s) in TEI header = Scripts for clustering, see folder "code"
- Create script to add information as tags (in body) to write in XML (in work)
Lemmatization/Normalisation
-
Done: Wordlist and Frequencies
-
ToDo: POS tagging
Named Entities
-
Names of persons: done A-D
-
Names of places: done A-K
Visualization
Word-Cluster
Visualization
(using fasttext) https://github.com/mmznr/Staatsarchiv-GLAMhack/tree/master/Visualisierungen/clusters.png https://github.com/mmznr/Staatsarchiv-GLAMhack/tree/master/Visualisierungen/clusters2.png
{kind=link}
{kind=link}
Frequency list of Word-Cluster
https://docs.google.com/spreadsheets/d/1rFo7p9YsQRwJufMuWGw2677acOsWevcmm-lN5RVBJv4/edit?usp=sharing
GIS Visualization
https://beta.observablehq.com/@mmznrstat/sex-and-crime-und-kneipenschlagereien-in-der-fruhen-neuzei
-
Done: Borders from swisstopo via Linked Data, Matching of the settlements of the canton of Zurich
-
ToDo: Get List of old names of this settlements, match them and show all relating documents of a settlement (or municipality)
SPARQLfish
New Frontiers in Graph Queries
We begin with the observation that a typical SPARQL endpoint is not friendly in the eyes of an average user. Typical users of cultural databases include researchers in the humanities, museum professionals and the general public. Few of these people have any coding experience and few would feel comfortable translating their questions into a SPARQL query.
Moreover, the majority of the users expect searches of online collections to take something like the form of a regular Google search (names, a few words, or at the top end Boolean operators). This approach to search does not make use of the full potential of the graph-type databases that typically make SPARQL endpoints available. It simply does not occur to an average user to ask the database a query of the type "show me all book authors whose children or grandchildren were artists."
The extensive possibilities that are offered by graph databases to researchers in the humanities go unexplored because of a lack of awareness of their capabilities and a shortage of information about how to exploit them. Even those academics who understand the potential of these resources and have some experience in using them, it is often difficult to get an overview of the semantics of complex datasets.
We therefore set out to develop a tool that:
-
simplifies the entry point of a SPARQL query into a form that is accessible to any user
-
opens ways to increase the awareness of users about the possibilities for querying graph databases
-
moves away from purely text-based searches to interfaces that are more visual
-
gives an overview to a user of what kinds of nodes and relations are available in a database
-
makes it possible to explore the data in a graphical way
-
makes it possible to formulate fundamentally new questions
-
makes it possible to work with the data in new ways
-
can eventually be applied to any SPARQL endpoint
https://github.com/sparqlfish/sparqlfish
Data
Wikidata
Team
- Loïc Jaouen loic.jaouen@unil.ch
- (Elena Chestnova elena.chestnova@usi.ch)
Swiss Art Stories on Twitter
In the project "Swiss art stories on Twitter", the Twitter bot "larthippie" has been created. The idea of the project is to automatically tweet information on Swiss art, artists and exhibitions.
Originally, different storylines for the tweets were discussed and programmed, such as:
-
Tweeting information about upcoming exhibitions at Kunsthaus Zürich and reminders with approaching deadlines
-
Tweets with specific information about artists, taken from the artists database SIK-ISEA
-
Tweeting the exhibition history of Kunsthaus Zürich
-
Comparing the images of artworks, created in the same year, held at the same location or showing the same subject
The prototype however has another focus now. It tweets the ownership history (provenance) of artworks. As the the information is scientifically researched, larthipppie provides tweets for art professionals. Therefore the twitter bot is more than a usual social media account, but might become a tool for provenance research. Interested audience has to follow larthippie in order to be updated on new provenance information. As an additional feature, the twitterbot larthippie likes and follows accounts that shares content from Swiss artists.
Followers can message the bot and ask for information about a painting on any artist. In the prototype, it is only possible to query the provenance of artworks by Ferdinand Hodler. In the future, the twitter bot might also tweet newly acquired works in art museums.
You can check the account by the following link: https://twitter.com/larthippie
Data
-
Swiss Institute for Art Research (SIK-ISEA)
-
Kunsthaus Zürich
-
Swiss National Museum
Team
- Tugrulcan Elmas, tugrulcanelmas@gmail.com, @tugrulcanelmas
Walking Around the Globe
a VR Picture Expedition
With our Hackathon prototype for a virtual 3D exhibition in VR we tackle several challenges.
-
The challenge of exhibition space: many collections, especially small ones -- like the Collection of Astronomical Instruments of ETH Zurich -- have only a small or no physical space at all to exhibit their objects to the public
-
The challenge of exhibiting light-sensitive artworks: some artworks -- especially art on paper -- are very sensitive to the light and are in danger of serious damaged when they are permanently exposed. That's why the Graphische Sammlung ETH Zurich can't present their treasures in a permanent exhibition to the public
-
The challenge of involving the public: nowadays the visitors do not want to be reduced to be passive consumers, they want and appreciate active involvement
-
The challenge of the scale: in usual 2D digital presentations the user does not get information about the real scale of the artworks and gets wrong ideas about the dimensions
-
The challenge of showing 3D objects in the digital space: many museum databases show only one or two digital images of their 3D objects, so the user gets only a very limited impression
Our Hackathon prototype for a virtual 3D exhibition in VR
-
offers unlimited exhibition space in the virtual reality
-
makes it possible to exhibit light sensitive artworks permanently using their digital reproductions
-
involves the public inviting them to slip into the role of the curator
-
shows the artwork in the correct scale
-
and gives the users the opportunity to walk around the 3D objects in the virtual space
A representative screenshot:

We unveil a window into a future where you can create, curate and experience virtual 3D expositions in VR. We showcase a first exposition with a 3D-Model of a globe like in the Collection of Astronomical Instruments of ETH Zurich as a centerpiece and works of art from the Graphische Sammlung ETH Zurich surrounding it. Users can experience our curated exposition using a state-of-the-Art VR headset, the HTC Vive.
Our vision has massive value for practitioners, educators and students and also opens up the experience of curation to a broader audience. It enables art to truly transcend borders, cultures and economic boundaries.
Project Presentation
You can download the presentation slides: 20181028_glamhack_presentation.pdf.
Project Impressions
On the very first day, we create our data model on paper by ensuring everybody got a chance to present their use cases, stories and needs. 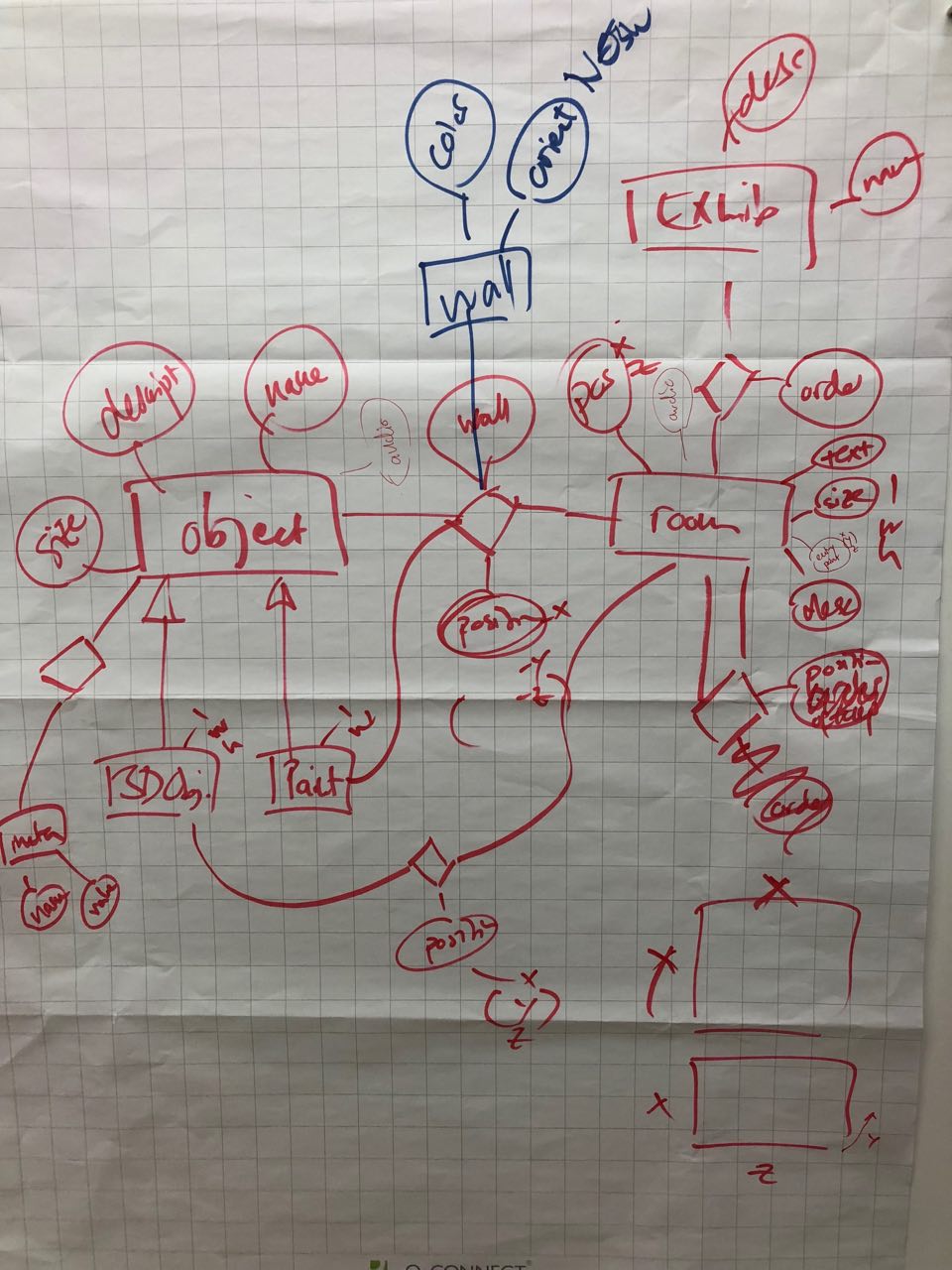
On Friday evening, we had a first prototype of our VR Environment: 
On Saturday, we created our interim presentation, improved our prototype, curated our exposition, and tried and ditched many ideas.
Saturday evening saw our prototype almost finished! Below a screenshot of two rooms, one curated by experts and the other one containing artificially generated art. 

Our final project status involves a polished prototype with an example exhibition consisting of two rooms:
Walking Around The Globe: A room curated by art experts, exhibiting a selection of old masterpieces (15th century to today).
Style transfer: A room designed by laymen showing famous paintings & derivates generated by an artificial intelligence (AI) via a technique called style transfer.

In the end we even created a mockup of the possible backend ui, the following images are some impressions for it:
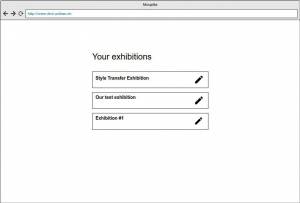
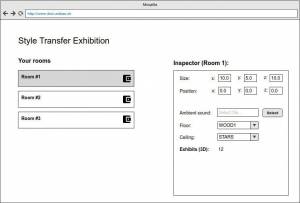
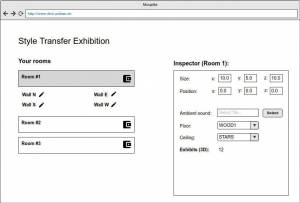
Technical Information
Our code is on Github, both the Frontend and the Backend.
We are using Unity with the SteamVR Plugin to deploy on the HTC Vive. This combination means we had to use combinations of C# Scripting (We recommend the excellent Rider Editor), design using the Unity Editor, custom modifications to the SteamVR plugin, do 3d model imports using FastObjImporter and other fun stuff.
Our backend is written in Java and uses MongoDB.
For the style transfer images, we used a open source python code which is available on Github.
Acknowledgments
The Databases and Information Systems Group at the University of Basel is the home of a majority of our project members. Our hardware was borrowed for the weekend from the Gravis Group from Prof. Vetter.
Data
- Dataset with digital images (jpg) and metadata (xml) from the Collection of Astronomical Instruments of ETH Zurich
- Graphische Sammlung ETH Zurich, Collection Online, four sample datasets with focus on bodies in the air, portraits, an artist (Rembrandt) and different techniques (printmaking and drawing)
Team
- Ivan Giangreco, Postdoc @ Databases and Information Systems Group
- Ralph Gasser, PhD Student @ Databases and Information Systems Group
- Mahnaz Amiri Parian, PhD Student @ Databases and Information Systems Group
- Silvan Heller, PhD Student @ Databases and Information Systems Group
- Loris Sauter, MsC Student @ Computer Science Uni Basel
- Ann-Kathrin Seyffer @ Graphische Sammlung ETH Zürich
- Susanne Pollack @ Graphische Sammlung ETH Zürich
- Agnese Quadri @ ETH Library
- Donatella Gavrilovich @ University of Rome "Tor Vergata"
Virtual Exhibitions
Create and visit virtual reality exhibitions with an HTC Vive and Unity3D in the virtual museum VIRTUE.
Components
- Front-end: Virtual Exhibition Presenter (VREP, this repository) at https://github.com/VIRTUE-DBIS/virtual-exhibition-presenter
- Back-end: Virtual Exhibition Manager (VREM) at https://github.com/dbisUnibas/virtual-exhibition-manager
- Example for a static exhibition: https://github.com/VIRTUE-DBIS/vre-mixnhack19
Please consult the Wiki or consider reading the Getting Started guide for setup and usage.
Core Features
- Virtual 3D world with positioned art objects
- Freely movable character (player)
- Support for multiple, interchangeable exhibitions
- Static pre-defined or automatically generated exhibition rooms
Getting Started
- Have a HTC Vive / SteamVR setup. For the installation process, check the manual.
- Start Unity3D.
- On the start screen click the
Openbutton. - Select this repository.
- Get yourself the backend.
- Start the backend.
- Feed the backend with an exhibition. If you want to make use of automatically generated coherent exhibitions, check out the Wiki.
- Adjust the configuration file
settings.jsonof VREP accordingly to your setup. - Start the incredible immersive experience of having an exhibition at your place.
Contributors
- Ralph Gasser
- Ivan Giangreco
- Silvan Heller
- Mahnaz Parian
- Loris Sauter
- Florian Spiess
- Simon Peterhans
- Rahel Arnold
- Maurizio Pasquinelli
This piece of software originates from the 4th Swiss Open Cultural Data Hackathon. Read more about our project on the Opendata Wiki.
We-Art-o-nauts
How to Provide a Better Art Experience
A better way to experience art: Build a working, easy to follow example that integrates open and curated culture data with VR devices in a museum exhibition to provide modern, fun and richer visitor experience. Focusing on one art piece, organizing data alone the timeline, building a concept and process, so anyone who want to use above technologies can easily follow the steps for any art object for any museum.
Have a VR device next to the painting, we integrate interesting facts about the painting in a 360 timeline view with voice over. Visitors can simply put it on to use it.
Try the live demo in your browser - works particularly well on mobile phones, and supports Google Cardboard:
Visit the project homepage for more information, and to learn more about the technology and data used.
See also: hackathon presentation (PPTX) | source code (GitHub)
Data
- "Allianzteppich", a permanent collection in Landsmuseum
- Curated data from Dominik Sievi in Landsmuseum
- Open data sources (WikiData)
Team
- Kamontat Chantrachirathumrong (Developer)
- Oleg Lavrovsky (Developer)
- Marina Pardini (UX designer)
- Birk Weiberg (Art Historian)
- Xia Willuhn (Developer)
The goal of this #GLAMhack project is to enhance the appreciation of art through deeper context. For more background see our website https://we-art-o-nauts.github.io/
To contribute, just download the repository and edit index.html in a text editor. There are some resources in the data folder, and scripts we depend on in js.
Demo: schoolofdata.ch/workshops/2018/weartonauts/
Background
During the 2018 Open Cultural Data Hackathon at the Swiss National Museum, we were impressed by a huge tapestry that is currently part of the permanent collection - the Allianzteppich (nationalmuseum.ch)
The museum people shared all the data available on the object with us, and we further researched information online to create a timeline of events surrounding its creation and history. In particular, Der Allianzteppich und die Fragen von Selbstdarstellung, Repräsentation und Rezeption by Sigrid Pallmert was of interest.
Although there is some information on the Wikipedia article Bildwirkerei, we could find very little on the technical term Wollwirkerei used in the catalog. The question of how to make information about the methods and history of art objects fascinated our team.
Tech
We created a spreadsheet using the Timeline JS template, and our code accesses the document published using Google Docs, so that the timeline could be visualized both in the original "2D form" and our 3D edition.
We are using the Virtual/Augmented Reality toolkit from Mozilla called A-Frame.
Text-to-speech voiceovers are generated with Responsive Voice.
Instructions
- Download this repository to your computer (e.g. GitHub Desktop) and open the folder with the project.
- In a command line (Mac: Terminal), go to the project folder using the cd (change directory) command, e.g.:
cd /Users/marinapardini/GitHub/weartonauts - Type a Python command to start a webserver:
python -m http.server - Make sure the phone and the computer are connected to the same network (
opendatach) - You will see something like "Serving HTTP on 0.0.0.0 port 8000". Open the Web browser on the phone to the address of your network connection (something like 192.168.7.123 instead of 0.0.0.0) but with the appropriate port number, e.g. type
192.168.7.123:8000 - If everything loads up, you should see a little cardboard icon. Tap it.
Team
- Marina Pardini (UX designer)
- Kamontat Chantrachirathumrong (Developer)
- Xia Willuhn (Developer)
- Oleg Lavrovsky (Developer)
- Birk Weiberg (Expert)
Wikidata-based multilingual library search
A library resource discovery portal designed and developed for libraries by libraries
In Switzerland each linguistic region is working with different authority files for authors and organizations, situation which brings difficulties for the end user when he is doing a search.

Goal of the Hackathon: work on a innovative solution as the library landscape search platforms will change in next years. Possible solution: Multilingual Entity File which links to GND, BnF, ICCU Authority files and Wikidata to bring end user information about authors in the language he wants.

Steps:
-
analyse coverage by wikidata of the RERO authority file (20-30%)
-
testing approach to load some RERO authorities in wikidata (learn process)
-
create an intermediate process using GND ID to get description information and wikidata ID
-
from wikidata get the others identifiers (BnF, RERO,etc)
-
analyse which element from the GND are in wikidata, same for BnF, VIAF and ICCU
-
create a multilingual search prototype (based on Swissbib model)
Data
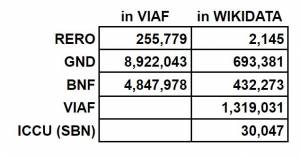
Number of ID in VIAF
-
BNF: 4847978
-
GND: 8922043
-
RERO: 255779
Number of ID in Wikidata from
-
BNF: 432273
-
GND: 693381
-
RERO: 2145
-
ICCU: 30047
-
VIAF: 1319031 (many duplicates: a WD-entity can have more than one VIAF ID)
Query model:
wikidata item with rero id
#All items with a property
Sample to query all values of a property
Property talk pages on Wikidata include basic queries adapted to each
property SELECT ?item ?itemLabel ?value ?valueLabel
valueLabel is only useful for properties with item-datatype
WHERE { ?item wdt:P3065 ?value
change P1800 to another property
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". } }
remove or change limit for more results
LIMIT 10000
Email from the GND :
There is currently no process that guarantees 100% coverage of GND entities in wikibase. The existing links between wikibase and GND entries come mostly from manually edited Wikipedia entries.
User Interface
There are several different target users: the librarians who currently use all kinds of different systems and the end user, who wants to search for information or to locate a book in a nearby library.
Librarian: The question of process is the key challenge concerning the librarian user. At present some Swiss librarians create authority records and some don't. New rules and processes for creating authority files in GND , BNF, etc will change their work methods. The process of creating local Swiss authority files will be entirely revamped. Fragmented Swiss regional authority files will disappear, and be replaced by either the German, French, Italian, American etc national authority files or by direct creation in Wikidata by the local librarian. (Wikidata will serve as central repository for all autority IDs).
End User The model for the multilingual user interface is SwissBib, the "catalog of Swiss univerity libraries, the Swiss national library, several cantonal libraries and other institutions". The objective is to keep the look and functionalities of the existing website, which includes multilingual display of labels in English, French, German and Italian.
What changes is the source of information about the author which will in the future be taken from the BNF for French, the GNB for German, and LCCN for English. (In the proof of concept pilot, only the author name will be concerned.)
The list of books and libraries will continue to function as before, with no changes.
In the full project, several pages must be modified:
-
The search page (example with Joel Dicker): https://www.swissbib.ch/Search/Results?lookfor=joel+dicker&type=AllFields
-
The Advanced search page https://www.swissbib.ch/Search/Advanced
-
The Record Page: https://www.swissbib.ch/Record/48096257X
The Proof on Concept project will focus exclusively on the basic search page.
Open issues The issue of key words remains open (at present they are from DNB, which works for German and English, but does not work for French)
The question of an author photo and a bio is open. At present very few authors have a short bio paragraph associated with their names. Should each author have a photo and bio? If so, where to put it on the page?
Other design question: Should the selection of the language of the book be moved up on the page?
Prototype
(Translations from Wikidata into French)
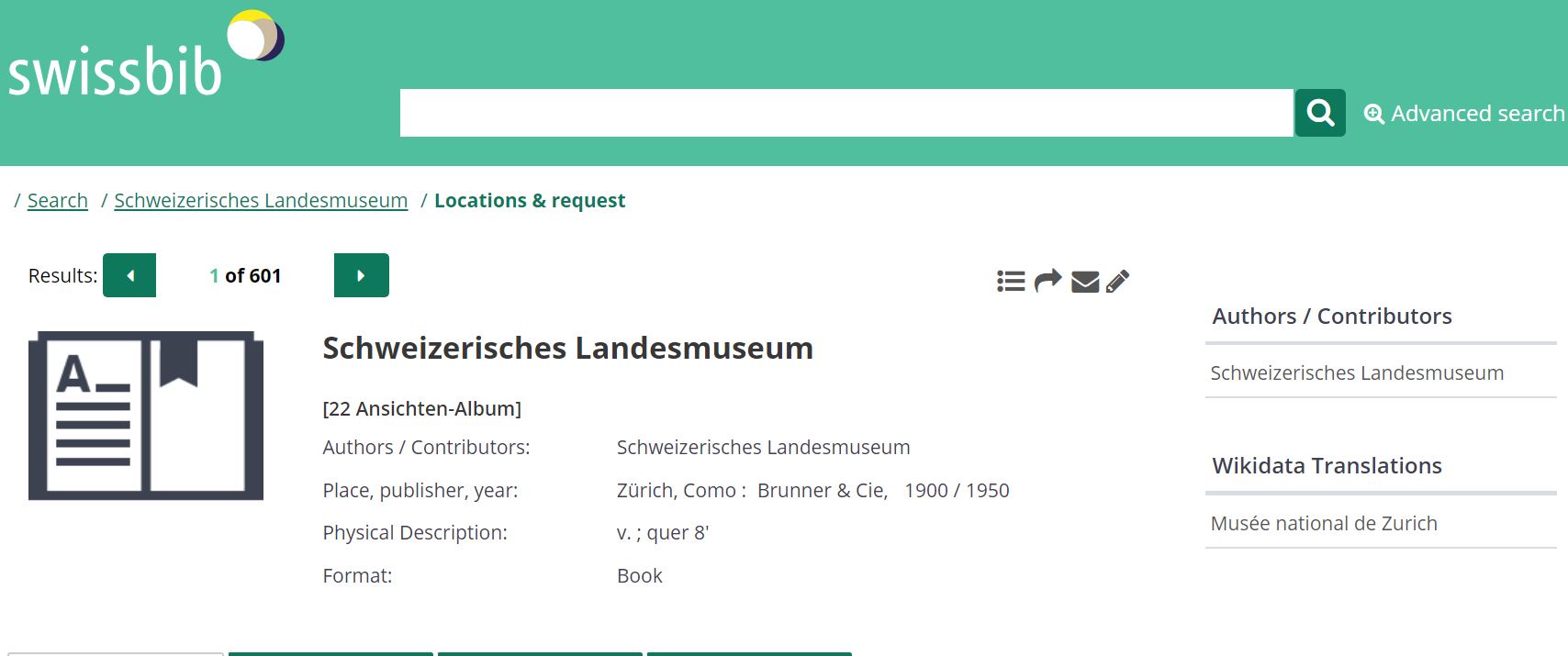
1. Schweizerisches Landesmuseum
http://feature.swissbib.ch/Record/110393589
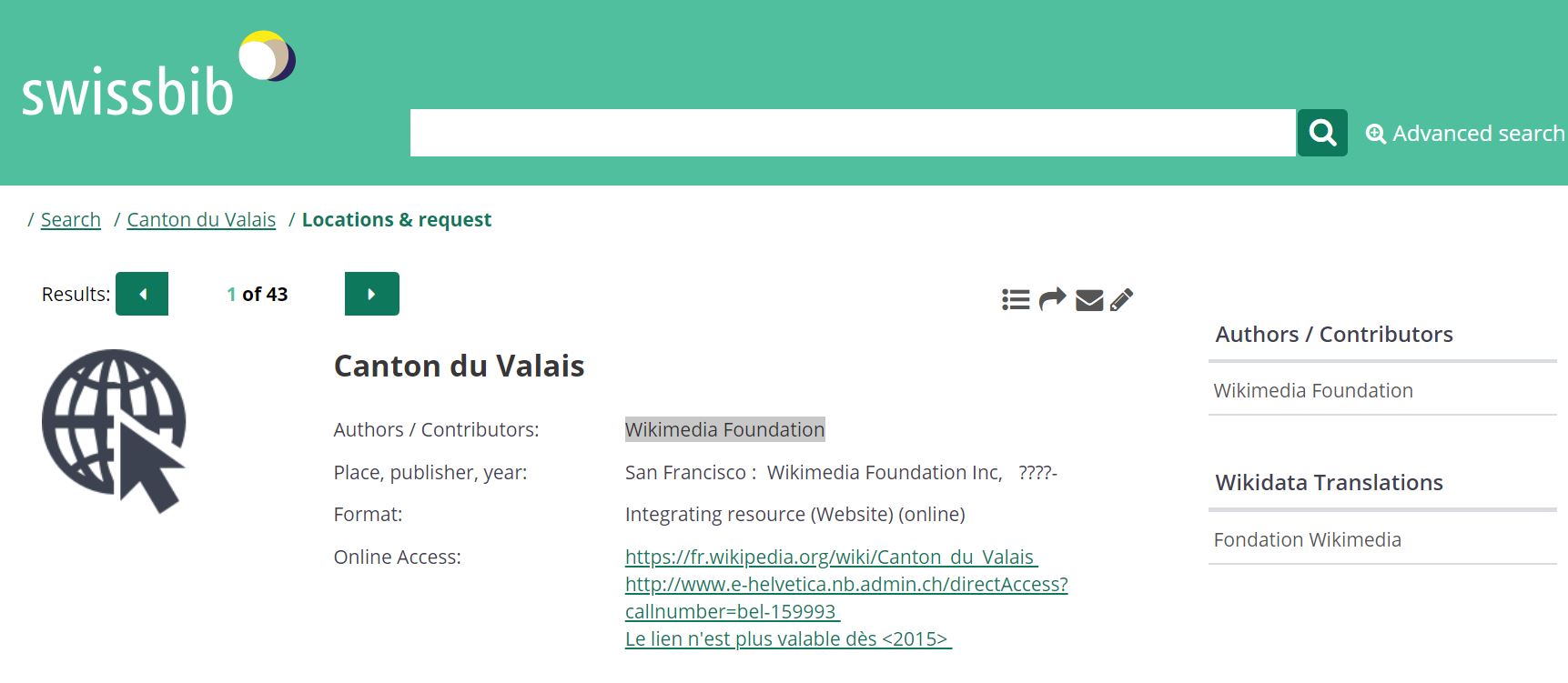
2. Wikimedia Foundation
http://feature.swissbib.ch/Record/070092974
3. Chocoladefabriken Lindt & Sprüngli AG
http://feature.swissbib.ch/Record/279360789
ATTENTION: Multiple authors

4. Verband schweizerischer Antiquare und Kunsthändler
ATTENTION: NO French label in Wikidata
http://feature.swissbib.ch/Record/107734591
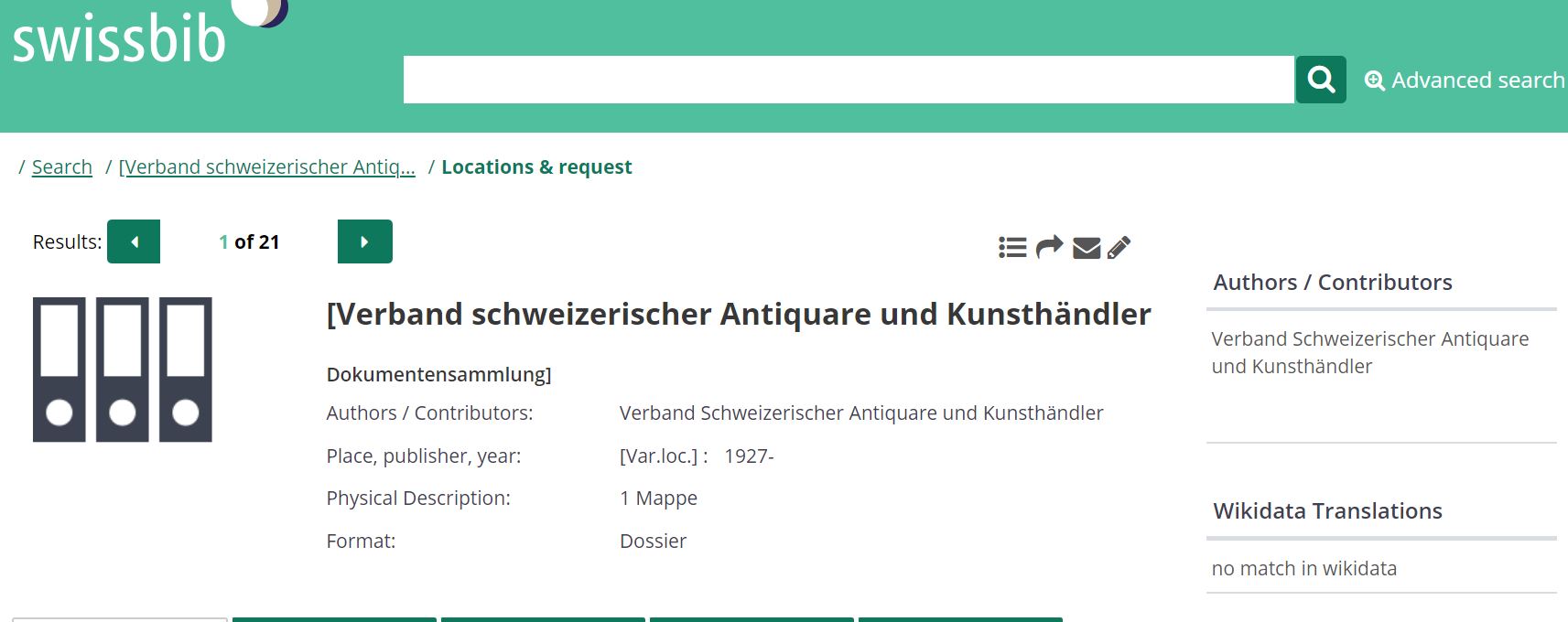
Methods
Way of getting BNF records via SRU from Wikidata
Instruction: add prefix "ark:/12148/cb" to BNF ID in order to obtain the ARK ID
Lookup Qcode from GND ID
SELECT DISTINCT ?item ?itemLabel WHERE { ?item wdt:P227 "1027690041". SERVICE wikibase:label { bd:serviceParam wikibase:language "en". } }
Integration of RERO person/organisation data into Wikidata
Methodology
4 cases
1. RERO authorities are in Wikidata with RERO ID
- 2145 items
2. RERO authorities are in Wikidata without RERO ID but with VIAF ID
-
1316347 items (without deduplication)
-
add only ID possibles (PetScan)
3. RERO authorities are in Wikidata without RERO or VIAF ID
- reconcialiation with OpenRefine
4. RERO authorities are not in Wikidata
- Quickstatements or mass import
Demo / Code / Final presentation
- Demo http://feature.swissbib.ch/Record/317008587 and you can search other records
- Code https://github.com/swissbib/vufind/tree/feature/wikidata-based-multilingual
- Final presentation : presentation.pdf
Team
- Elena Gretillat
- Nicolas Prongué
- Lionel Walter
- Laurel Zuckerman
- Jacqueline Martinelli
VuFind
Now on Gitlab
UB Basel work on VuFind has moved to gitlab : https://gitlab.com/swissbib/classic/vufind
VuFind
VuFind is an open source discovery environment for searching a collection of records. To learn more, visit https://vufind.org.
Zurich historical photo tours
We would like to enable our users to discover historical pictures of Zürich and go to the places where they were taken. They can take the perspective of the photographer from around 100 years ago and see how the places have changed. They can also share their photographs with the community. We have planned two thematic tours, one with historical photographs of Adolphe Braun and one with photographs connected to the subject of silk fabrication. The tour is enhanced with some historical information. In the collections of the ETH, Baugeschichtliches Archiv, and Zentralbibliothek Zurich, Graphische Sammlung, we found pictures to match the topics above and to set up a nice tour for the users. In a second step we went to the actual spots to verify if the pictures could be taken and to find out the exact geodata. Meanwhile, our programmers inserted the photographer's stops on a map. As soon as the users reach the proximity of the spot, their phone will start vibrating. At this point, the historical photo will show up and the task is to search for the right angle from where the historical photograph has been taken. At this point, the users are asked to take their own picture. The app allows the users to overlay the historical with the current picture so a comparison can be made. The user is provided by additional information like the name of the photographer of the historical picture, links to the collection the picture comes from, the building itself, connection to the silk industry etc. Here is the link to our prototype: https://glamhistorytour.github.io/HistoryTourApp/
Data
-
Open images from http://ba.e-pics.ethz.ch/#1540897299565_1|E-Pics
-
Open images from https://www.e-manuscripta.ch/
-
Open images from https://www.silkmemory.ch/
-
Open images from https://opendata.swiss/dataset/vues-de-la-suisse
Team
- Maya Beer
- Rafael Arizcorreta
- Tina Tomovic
- Annabelle Wiegart
- Lothar Schmitt
- Thomas Bochet
- Marina Petrova
- Kenny Floria