
Report
💡 Active projects and challenges as of 21.07.2026 21:54.
Hide text CSV Data Package Print
Big Data Analytics
(bibliographical data)
We try to analyse bibliographical data using big data technology (flink, elasticsearch, metafacture).
Here a first sketch of what we're aiming at:
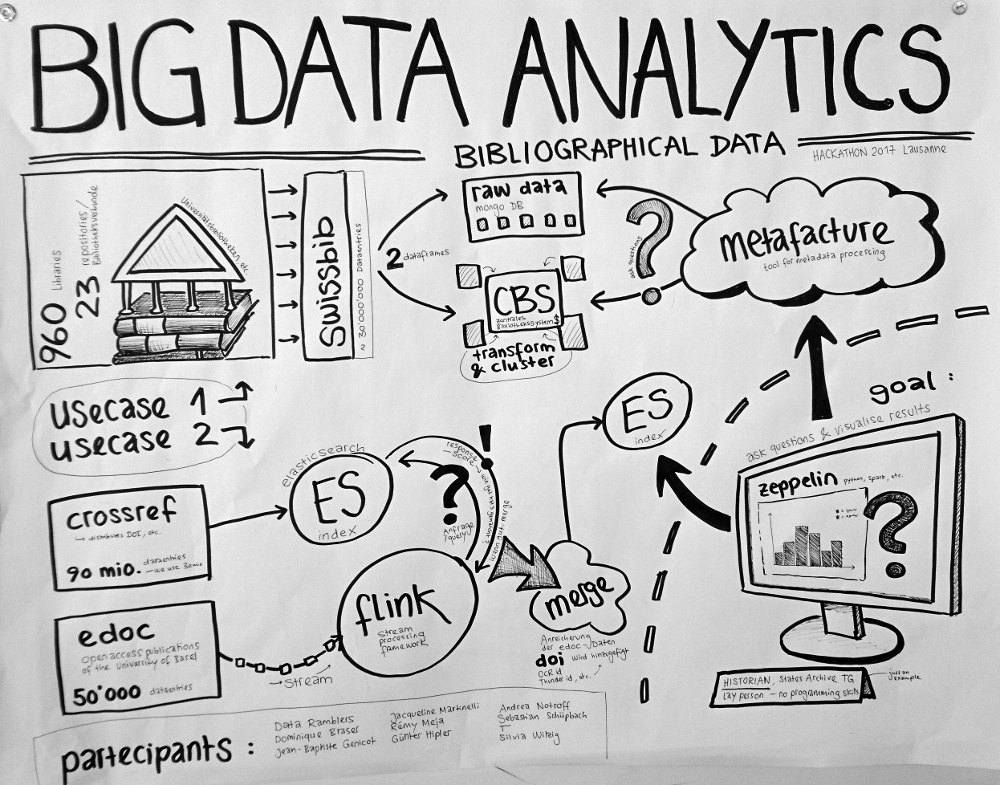
Datasets
We use bibliographical metadata:
Swissbib bibliographical data https://www.swissbib.ch/
-
Catalog of all the Swiss University Libraries, the Swiss National Library, etc.
-
960 Libraries / 23 repositories (Bibliotheksverbunde)
-
ca. 30 Mio records
-
MARC21 XML Format
-
→ raw data stored in Mongo DB
-
→ transformed and clustered data stored in CBS (central library system)
-
Institutional Repository der Universität Basel (Dokumentenserver, Open Access Publications)
-
ca. 50'000 records
-
JSON File
crossref https://www.crossref.org/
-
Digital Object Identifier (DOI) Registration Agency
-
ca. 90 Mio records (we only use 30 Mio)
-
JSON scraped from API
Use Cases
Swissbib
Librarian:
-
For prioritizing which of our holdings should be digitized most urgently, I want to know which of our holdings are nowhere else to be found.
-
We would like to have a list of all the DVDs in swissbib.
-
What is special about the holdings of some library/institution? Profile?
Data analyst:
- I want to get to know better my data. And be faster.
→ e.g. I want to know which records don't have any entry for ‚year of publication'. I want to analyze, if these records should be sent through the merging process of CBS. Therefore I also want to know, if these records contain other ‚relevant' fields, defined by CBS (e.g. ISBN, etc.). To analyze the results, a visualization tool might be useful.
edoc
Goal: Enrichment. I want to add missing identifiers (e.g. DOIs, ORCID, funder IDs) to the edoc dataset.
→ Match the two datasets by author and title
→ Quality of the matches? (score)
Tools
elasticsearch https://www.elastic.co/de/
JAVA based search engine, results exported in JSON
Flink https://flink.apache.org/
open-source stream processing framework
Metafacture https://culturegraph.github.io/, https://github.com/dataramblers/hackathon17/wiki#metafacture
Tool suite for metadata-processing and transformation
Zeppelin https://zeppelin.apache.org/
Visualisation of the results
How to get there
Usecase 1: Swissbib
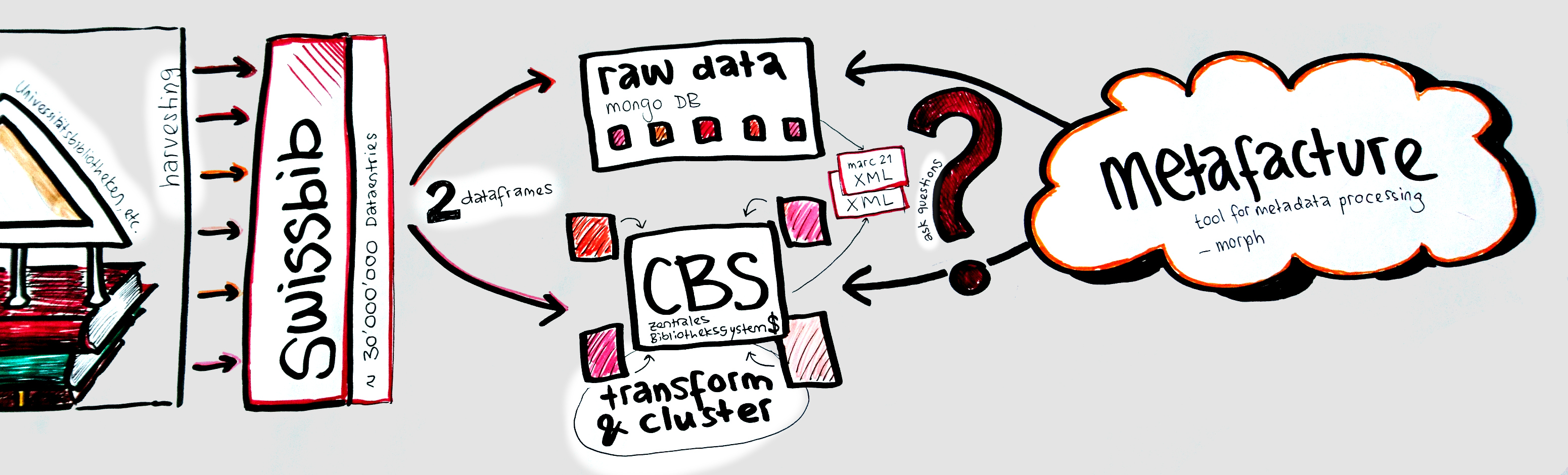
Usecase 2: edoc
Links
Data Ramblers Project Wiki https://github.com/dataramblers/hackathon17/wiki
Team
- Data Ramblers https://github.com/dataramblers
- Dominique Blaser
- Jean-Baptiste Genicot
- Günter Hipler
- Jacqueline Martinelli
- Rémy Mej
- Andrea Notroff
- Sebastian Schüpbach
- T
- Silvia Witzig
hackathon17
Files and notes about the Swiss Open Cultural Data Hackathon 2017. For information about the data, use cases, tools, etc, see the Wiki: https://github.com/dataramblers/hackathon17/wiki
Requirements
Elasticsearch cluster
-
see https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html (especially paragraph on production mode)
-
Elasticsearch requires increased virtual memory. See: https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html
Docker
- Docker CE, most recent version
- recommended: 17.06
- see also hints.md
Docker Compose
- most recent version
- see also hints.md
Installation notes
The technical environment runs in Docker containers. This enables everyone to run the infrastructure locally on their computers provided that Docker and Docker Compose are installed.
How to install Docker and Docker Compose
The package sources of many (Linux-) distributions do not contain the most recent version of Docker, and do not contain Docker Compose at all. You must most likely install them manually.
- Install Docker CE, preferably 17.06.
- https://docs.docker.com/engine/installation/
- Verify correct installation:
sudo docker run hello-world
- Install Docker-Compose.
- https://docs.docker.com/compose/install/
- Check installed version:
docker-compose --version
- Clone this repository.
git clone git@github.com:dataramblers/hackathon17.git
- Increase your virtual memory: https://www.elastic.co/guide/en/elasticsearch/reference/current/vm-max-map-count.html
How to run the technical environment in Docker (for Linux users)
Use sudo for Docker commands.
- Make sure you have sufficient virtual memory:
sysctl vm.max_map_countmust output at least262144.
- To increase the limits for one session:
sudo sysctl -w vm.max_map_count=262144 - To increase the limits permanently:
- Create a new
.conffile in/etc/sysctl.d/(e.g.10-vm-max-map-count.conf, the prefix number just indicating the order in which the files are parsed) - Add the line
vm.max_map_count=262144and save the file - Reread values for sysctl:
sudo sysctl -p --system
- Create a new
cdto yourhackathon17directory.docker-compose up-> Docker loads the images and initializes the containers- Access to the running applications:
- Elasticsearch HTTP:
localhost:9200 - Elasticsearch TCP:
localhost:9300 - Zeppelin instance:
localhost:8080 - Flink RPC:
localhost:6123 - Dashboard of the Flink cluster:
localhost:8081
- If you want to stop and exit the docker containers:
docker-compose down(in separate terminal) orCtrl-c(in same terminal)
Collaborative Face Recognition
With Picture Annotation for Archives
Les Archives photographiques de la Société des Nations (SDN) --- ancêtre de l'actuelle Organisation des Nations Unies (ONU) --- consistent en une collection de plusieurs milliers de photographies des assemblées, délégations, commissions, secrétariats ainsi qu'une série de portraits de diplomates. Si ces photographies, numérisées en 2001, ont été rendues accessible sur le web par l'Université de l'Indiana, celles-ci sont dépourvues de métadonnées et sont difficilement exploitables pour la recherche.
Notre projet est de valoriser cette collection en créant une infrastructure qui soit capable de détecter les visages des individus présents sur les photographies, de les classer par similarité et d'offrir une interface qui permette aux historiens de valider leur identification et de leur ajouter des métadonnées.
Le projet s'est déroulé sur deux sessions de travail, en mai (Geneva Open Libraries) et en septembre 2017 (3rd Swiss Open Cultural Data Hackathon), séparées ci-dessous.
Session 2 (sept. 2017)
L'équipe
| Université de Lausanne | United Nations Archives | EPITECH Lyon | Université de Genève |
|---|---|---|---|
| Martin Grandjean | Blandine Blukacz-Louisfert | Gregoire Lodi | Samuel Freitas |
| \ | |||
| Colin Wells | \ | ||
| \ | |||
| \ | |||
| \ | |||
| Adrien Bayles | \ | ||
| \ | |||
| \ | |||
| Sifdine Haddou | \ | ||
Compte-Rendu
Dans le cadre de la troisième édition du Swiss Open Cultural Data Hackathon, l'équipe qui s'était constituée lors du pre-event de Genève s'est retrouvée à l'Université de Lausanne les 15 et 16 septembre 2017 dans le but de réactualiser le projet et poursuivre son développement.
Vendredi 15 septembre 2017
Les discussions de la matinée se sont concentrées sur les stratégies de conception d'un système permettant de relier les images aux métadonnées, et de la pertinence des informations retenues et visibles directement depuis la plateforme. La question des droits reposant sur les photographies de la Société des Nations n'étant pas clairement résolue, il a été décidé de concevoir une plateforme pouvant servir plus largement à d'autres banques d'images de nature similaire.
Samedi 16 septembre 2017
 Découverte : Wikimedia Commons dispose de son propre outil d'annotation : ImageAnnotator. Voir exemple ci-contre.
Découverte : Wikimedia Commons dispose de son propre outil d'annotation : ImageAnnotator. Voir exemple ci-contre.
Code
Organisation
https://github.com/PictureAnnotation
Repositories
https://github.com/PictureAnnotation/Annotation
https://github.com/PictureAnnotation/Annotation-API
Data
Images en ligne sur Wikimedia Commons avec identification basique pour tests :
A (1939) https://commons.wikimedia.org/wiki/File:League_of_Nations_Commission_075.tif

B (1924-1927) https://commons.wikimedia.org/wiki/File:League_of_Nations_Commission_067.tif

{kind=link}
Session 1 (mai 2017)
L'équipe
| Université de Lausanne | United Nations Archives | EPITECH Lyon | Archives d'Etat de Genève |
|---|---|---|---|
| Martin Grandjean martin.grandjean@unil.ch | Blandine Blukacz-Louisfert bblukacz-louisfert@unog.ch | Adam Krim adam.krim@epitech.eu | Anouk Dunant Gonzenbach anouk.dunant-gonzenbach@etat.ge.ch |
| \ | |||
| Colin Wells cwells@unog.ch | \ | ||
| \ | |||
| \ | |||
| Maria Jose Lloret mjlloret@unog.ch | Adrien Bayles adrien.bayles@epitech.eu | \ | |
| \ | |||
| \ | |||
| Paul Varé paul.vare@epitech.eu | \ | ||
![]()
Ce projet fait partie du Geneva Open Libraries Hackathon.
Compte-Rendu
Vendredi 12 mai 2017
Lancement du hackathon Geneva Open Libraries à la Bibliothèque de l'ONU (présentation du week-end, pitch d'idées de projets, ...)
Premières idées de projets:\
- Site avec tags collaboratifs pour permettre l'identification des personnes sur des photos d'archives.\
- Identification des personnages sur des photos d'archives de manière automatisée.
→ Identifier automatiquement toutes les photos où se situe la même personne et permettre l'édition manuelle de tags qui s'appliqueront sur toutes les photos du personnage (plus besoin d'identifier photo par photo les personnages photographiés).


Samedi 13 mai 2017
Idéalisation du projet: que peut-on faire de plus pour que le projet ne soit pas qu'un simple plugin d'identification ? Que peut-on apporter de novateur dans la recherche collaborative ? Que peut-on faire de plus que Wikipédia ? Travailler sur la photo, la manière dont les données sont montrées à l'utilisateur, etc...
Problématique de notre projet: permettre une collaboration sur l'identification de photos d'archives avec une partie automatisée et une partie communautaire et manuelle.
Analyser les photos → Identifier les personnages → Afficher la photo sur un site avec tous les personnages marqués ainsi que tous les liens et notes en rapports.
Utilisateur → Création de tags sur la photographie (objets, scènes, liens historiques, etc..) → Approbation de la communauté de l'exactitude des tags proposés.
Travail en cours sur le P.O.C.:\
- Front du site: partie graphique du site, survol des éléments...\
- Prototype de reconnaissance faciale: quelques défauts à corriger, exportation des visages...\
- Poster du projet




Dimanche 14 mai 2017
Le projet ayant été sélectionné pour représenter le hackathon Geneva Open Libraries lors de la cérémonie de clôture de l'Open Geneva Hackathons (un projet pour chacun des hackathons se tenant à Genève ce week-end), il est présenté sur la scène du Campus Biotech.




Data
Poster Genève - Mai 2017
Version PDF grande taille disponible ici. Version PNG pour le web ci-dessous.

Poster Lausanne - Sepembre 2017
Version PNG

Code
No longer available.
Hacking Gutenberg
A Moveable Type Game
The internet and the world wide web are often referred to as being disruptive. In fact, every new technology has a disruptive potential. 550 years ago the invention of the modern printing technology by Johannes Gutenberg in Germany (and, two decades later, by William Caxton in England) was massively disruptive. Books, carefully bound manuscripts written and copied by scribes during weeks, if not months, could suddenly be mass-produced at an incredible speed. As such the invention of moveable types, along with other basic book printing technologies, had a huge impact on science and society.
And yet, 15th century typographers were not only businessmen, they were artists as well. Early printing fonts reflect their artistic past rather than their industrial potential. The font design of 15th century types is quite obviously based on their handwritten predecessors. A new book, although produced by means of a new technology, was meant to be what books had been for centuries: precious documents, often decorated with magnificent illustrations. (Incunables -- books printed before 1500 -- often show a blank square in the upper left corner of a page so that illustrators could manually add artful initials after the printing process.)
Memory, also known as Match or Pairs, is a simple concentration game. Gutenberg Memory is an HTML 5 adaptation of the common tile-matching game. It can be played online and works on any device with a web browser. By concentrating on the tiles in order to remember their position the player is forced to focus on 15th (or early 16th) century typography and thus will discover the ageless elegance of the ancient letters.

Gutenberg Memory, Screenshot

Johannes Gutenberg: Biblia latina, part 2, fol. 36
Gutenberg Memory comes with 40 cards (hence 20 pairs) of syllables or letter combinations. The letters are taken from high resolution scans (>800 dpi) of late medieval book pages digitized by the university library of Basel. Given the original game with its 52 cards (26 pairs), Gutenberg Memory has been slightly simplified. Nevertheless it is rather hard to play as the player's visual orientation is constrained by the cards' typographic resemblance.
In addition, the background canvas shows a geographical map of Europe visualizing the place of printing. Basic bibliographic informations are given in the caption below, including a link to the original scan.
Instructions
Click on the cards in order to turn them face up. If two of them are identical, they will remain open, otherwise they will turn face down again. A counter indicates the number of moves you have made so far. You win the game as soon as you have successfully found all the pairs. Clicking (or tapping) on the congratulations banner, the close button or the restart button in the upper right corner will reshuffle the game and proceed to a different font, the origin of which will be displayed underneath.
Updates
2017/09/15 v1.0: Prototype, basic game engine (5 fonts)
2017/09/16 v2.0: Background visualization (place of printing)
2017/09/19 v2.1: Minor fixes
Data
-
Wikimedia Commons, 42-zeilige Gutenbergbibel, Teil 2, Blatt 36, Mainz, 1454-1455
-
Wikimedia Commons, 42-zeilige Gutenbergbibel, Teil 2, Blatt 35, Detail
-
Wikimedia Commons, Adam Petri, Martin Luther, Das Alte Testament deutsch, Basel, 1523-1525
-
Wikimedia Commons, Aldus Manutius, Horatius Flaccus, Opera, Venedig, 1501
-
Wikimedia Commons, Johannes Amerbach, Johannes Marius Philelphus, Epistolarium novum, Basel, 1486
-
Wikimedia Commons, Hieronymus Andreae, Albrecht Dürer, Underweysung der messung mit dem zirckel, Nürnberg 1525
Team

Elias Kreyenbühl (left), Thomas Weibel at the «Génopode» building on the University of Lausanne campus.
- Prof. Thomas Weibel, Thomas Weibel Multi & Media, University of Applied Sciences Chur
- Dr. des. Elias Kreyenbühl, University Library of Basel
Jung - Rilke Correspondence Networks
Joint project bringing together three separate projects: Rilke correspondance, Jung correspondance and ETH Library.
Objectives:
- agree on a common metadata structure for correspondence datasets
- clean and enrich the existing datasets
- build a database that can can be used not just by these two projects but others as well, and that works well with visualisation software in order to see correspondance networks
- experiment with existing visualization tools
Data
ACTUAL INPUT DATA
- For Jung correspondance: https://opendata.swiss/dataset/c-g-jung-correspondence (three files)
- For Rilke correspondance: https://opendata.swiss/en/dataset/handschriften-rainer-maria-rilke (two files, images and meta data)
Comment: The Rilke data is cleaner than the Jung data. Some cleaning needed to make them match: 1) separate sender and receiver; clean up and cluster (OpenRefine) 2) clean up dates and put in a format that IT developpers need (Perl) 3) clean up placenames and match to geolocators (Dariah-DE) 4) match senders and receivers to Wikidata where possible (Openrefine, problem with volume)
METADATA STRUCTURE
The follwing fields were included in the common basic data structure:
sysID; callNo; titel; sender; senderID; recipient; recipientID; place; placeLat; placeLong; datefrom, dateto; language
DATA CLEANSING AND ENRICHMENT
- Description of steps, and issues, in Process (please correct and refine).
Issues with the Jung correspondence is data structure. Sender and recipient in one column. Also dates need both cleaning for consistency (e.g. removal of "ca.") and transformation to meet developper specs. (Basil using Perl scripts)
For geocoding the placenames: OpenRefine was used for the normalization of the placenames and DARIAH GeoBrowser for the actual geocoding (there were some issues with handling large files). Tests with OpenRefine in combination with Open Street View were done as well.
The C.G. Jung dataset contains sending locations information for 16,619 out of 32,127 letters; 10,271 places were georeferenced. In the Rilke dataset all the sending location were georeferenced.
For matching senders and recipients to Wikidata Q-codes, OpenRefine was used. Issues encountered with large files and with recovering Q codes after successful matching, as well as need of scholarly expertise to ID people without clear identification. Specialist knowledge needed. Wikidata Q codes that Openrefine linked to seem to have disappeared? Instructions on how to add the Q codes are here https://github.com/OpenRefine/OpenRefine/wiki/reconciliation.
Doing this all at once poses some project management challenges, since several people may be working on same files to clean different data. Need to integrate all files.
DATA after cleaning:
https://github.com/basimar/hackathon17_jungrilke
DATABASE
Issues with the target database: Fields defined, SQL databases and visuablisation program being evaluated. How - and whether - to integrate with WIkidata still not clear.
Issues: letters are too detailed to be imported as Wikidata items, although it looks like the senders and recipients have the notability and networks to make it worthwhile. Trying to keep options open.
As IT guys are building the database to be used with the visualization tool, data is being cleaned and Q codes are being extracted. They took the cleaned CVS files, converted to SQL, then JSON.
Additional issues encountered:
- Visualization: three tools are being tested: 1) Paladio (Stanford) concerns about limits on large files? 2) Viseyes and 3) Gephi.
- Ensuring that the files from different projects respect same structure in final, cleaned-up versions.
Visualization (examples)

Heatmap of Rainer Maria Rilke's correspondence (visualized with Google Fusion Tables)

Correspondence from and to C. G. Jung visualized as a network. The two large nodes are Carl Gustav Jung (below) and his secretary's office (above). Visualized with the tool Gephi
Video of the presentation
Team
- Flor Méchain (Wikimedia CH): working on cleaning and matching with Wikidata Q codes using OpenRefine.
- Lena Heizman (Dodis / histHub): Mentoring with OpenRefine.
- Hugo Martin
- Samantha Weiss
- Michael Gasser (Archives, ETH Library): provider of the dataset C. G. Jung correspondence
- Irina Schubert
- Sylvie Béguelin
- Basil Marti
- Jérome Zbinden
- Deborah Kyburz
- Paul Varé
- Laurel Zuckerman
- Christiane Sibille (Dodis / histHub)
- Adrien Zemma
- Dominik Sievi wdparis2017
Medical History Collection
data for the glam2017
Finding connections and pathways between book and object collections of the University Institute for History of Medecine and Public Heatlh (Institute of Humanities in Medicine since 2018) of the CHUV.
The project started off with data sets concerning two collections: book collection and object collection, both held by the University Institute for History of Medicine and Public Health in Lausanne. They were metadata of the book collection, and metadata plus photographs of object collection. These collections are inventoried in two different databases, the first one accessible online for patrons and the other not.
The idea was therefore to find a way to offer a glimpse into the objet collection to a broad audience as well as to highlight the areas of convergence between the two collections and thus to enhance the patrimony held by our institution.
Juxtaposing the library classification and the list of categories used to describe the object collection, we have established a table of concordance. The table allowed us to find corresponding sets of items and to develop a prototype of a tool that allows presenting them conjointly: https://medicalhistorycollection.github.io/glam2017/.
Finally, we've seized the opportunity and uploaded photographs of about 100 objects on Wikimedia: https://commons.wikimedia.org/wiki/Category:Institut_universitaire_d'histoire_de_la_médecine_et_de_la_santé_publique.
Data
https://github.com/MedicalHistoryCollection/glam2017/tree/master/data
Team
- loic.jaouen
- Magdalena Czartoryjska Meier
- Rae Knowler
- Arturo Sanchez
- Roxane Fuschetto
- Radu Suciu
Swiss Open Cultural Data Hackathon 2017: Medical History Collection
Data and code relating to the Medical History Collection project for #GLAMHack2017.
Our data comes from the University Institute for History of Medicine and Public Health of the CHUV. We have the metadata of the entire book collection, and photographs + metadata of a section of the object collection. We aim to find connections and pathways between the two collections.
scripts
Data-cleaning scripts used to standardise and enhance the original datasets.
data
Cleaned datasets.
Links
- Project wiki page: http://make.opendata.ch/wiki/project:medicalhistorycollections
- #GLAMHack2017 page: http://make.opendata.ch/wiki/event:2017-09
- CHUV: http://www.chuv.ch/
Old-catholic Church Switzerland Historical Collection
Christkatholische Landeskirche der Schweiz: historische Dokumente
Der sog. "Kulturkampf" (1870-1886) (Auseinandersetzung zwischen dem modernen liberalen Rechtsstaat und der römisch-katholischen Kirche, die die verfassungsmässig garantierte Glaubens- und Gewissensfreiheit so nicht akzeptieren wollte) wurde in der Schweiz besonders heftig ausgefochten. Ausgewählte Dokumente in den Archiven der christkatholischen Landeskirche bilden diese interessante Phase zwischen 1870 und 1886/1900 exemplarisch ab. Als lokale Fallstudie (eine Kirchgemeinde wechselt von der römisch-katholischen zur christkatholischen Konfession) werden in der Kollektion die Protokolle der Kirchgemeinde Aarau (1868-1890) gemeinfrei publiziert (CC-BY Lizenz). Dazu werden die digitalisierten Zeitschriften seit 1873 aus der Westschweiz publiziert. Die entsprechenden Dokumente wurden von den Archivträgern (Eigner) zur gemeinfreien Nutzung offiziell genehmigt und freigegeben. Allfällige Urheberrechte sind abgelaufen (70 Jahre) mit Ausnahme von wenigen kirchlichen Zeitschriften, die aber sowieso Öffentlichkeitscharakter haben. Zielpublikum sind Historiker und Theologen sowie andere Interessierte aus Bildungsinstitutionen. Diese OpenData Kollektion soll andere christkatholische Gemeinden ermutigen weitere Quellen aus der Zeit des Kulturkampfes zu digitalisieren und zugänglich zu machen.
Overview
Bestände deutsche Schweiz :
- Kirchgemeinde Aarau
- Protokolle Kirchgemeinderat 1868-1890
- Monographie (1900) : Xaver Fischer : Abriss der Geschichte der katholischen (christkatholischen) Kirchgemeinde Aarau 1806-1895
Fonds Suisse Romande:
- Journaux 1873-2016
- Le Vieux-Catholique 1873
- Le Catholique-Suisse 1873-1875
- Le Catholique National 1876-1878
- Le Libéral 1878-1879
- La Fraternité 1883-1884
- Le Catholique National 1891-1908
- Le Sillon de Genève 1909-1910
- Le Sillon 1911-1970
- Présence 1971-2016
- Canton de Neuchâtel
- Le Buis 1932-2016
- Paroisse Catholique-Chrétienne de Genève: St.Germain (not yet published)
- Répertoire des archives (1874-1960)
- Conseil Supérieur - Arrêtés - 16 mai 1874 au 3 septembre 1875
- Conseil Supérieur Président - Correspondence - 2 janv 1875 - 9 sept 1876
The data will be hosted on christkatholisch.ch; the publication date will be communicated. Prior to this the entry (national register) on opendata.swiss must be available and approved.
Data
- Présence (2007-2016): http://www.catholique-chretien.ch/publica/archives.php
Team
OpenGuesser
A geographic #GLAMhack
This is a game about guessing and learning about geography through images and maps, made with Swisstopo's online maps of Switzerland. For several years this game was developed as open source, part of a series of GeoAdmin StoryMaps: you can try the original SwissGuesser game here, based on a dataset from the Swiss Federal Archives now hosted at Opendata.swiss.
The new version puts your orienteering of Swiss museums to the test.
Demo: OpenGuesser Demo
Encouraged by an excellent Wikidata workshop (slides) at #GLAMhack 2017, we are testing a new dataset of Swiss museums, their locations and photos, obtained via the Wikidata Linked Data endpoint (see app/data/*.sparql in the source). Visit this Wikidata Query for a preview of the first 10 results. This opens the possibility of connecting other sources, such as datasets tagged 'glam' on Opendata.swiss, and creating more custom games based on this engine.
We play-tested, revisited the data, then forked and started a refresh of the project. All libraries were updated, and we got rid of the old data loading mechanism, with the goal of connecting (later in real time) to open data sources. A bunch of improvement ideas are already proposed, and we would be glad to see more ideas and any contributions: please raise an Issue or Pull Request on GitHub if you're so inclined!
Data
- GeoAdmin API via OpenLayers
- Wikidata API
Team
- loleg
- @pa_fonta
OpenGuesser
This is a web game about guessing and learning about geography through imagea and maps, made with Swisstopo's GeoAdmin map of Switzerland.
After several years of development as a series of GeoAdmin Storymaps - try the original SwissGuesser game here - we play tested, forked and started a refresh of the project at #GLAMhack 2017.
We updated all library dependencies but got rid of the old data loading mechanism, with the goal of connecting (later in real time) to open data sources such as Wikidata/Commons.
A test is being done via the Wikidata Linked Data endpoint (see app/data/*.sparql), notably via datasets tagged 'glam' on Opendata.swiss for creating custom games.
There are a few other improvement ideas in mind already:
- Redesign the frontend to improve aesthetics and usability.
- Add a new title and tutorial, complete with loading sequence.
- Difficulty levels.
- Multiple guesses.
- Cooperative play (e.g. ghost traces of a friend's guesses)
- High scores.
- Sound f/x!
..and we would be glad to see more ideas and any contributions: please raise an Issue or PR if you're so inclined!
Authors
A number of people have worked on this project at some point. Please see contributors of the original project in geoadmin/mf-swissguesser
Installation
The project is built with OpenLayers, jQuery and the Bootstrap framework, with a collection of tools powered by Node.js.
- Install Node.js http://nodejs.org/download/
- Install dependencies from the Node Package Manager (or Yarn, etc.) with this command at the project root:
npm install
This will install Grunt and Bower automatically. However, it is recommended that they are installed globally:
npm install -g grunt-cli bower
Run this command as root to use system-wide, or use the nave.sh utility for your local user.
Install dependencies
bower install
(or node_modules/.bin/bower install)
For generating documentation, the Pygments utility is required, which can be installed as indicated on the website or on Ubuntu/Debian systems as follows:
# sudo apt-get install python-pygments
Preparing translations
With a similar process, translations for this app are in a spreadsheet. Export to CSV and save the resulting file under `/app/data/i18n/translation.csv'. Then run:
$ node util/translationCSV.js
Compiling resources
To a local server watching for changes, and open a browser:
$ grunt server
To create a docs/ folder with HTML documentation, run:
$ grunt docs
See Grunt documentation and Gruntfile.js for other commands.
Deploying releases
First you need to build the Bootstrap framework. From the app/bower_components/bootstrap/ folder run:
bootstrap$ npm install
bootstrap$ grunt dist
Now you can build this project's distribution folder.
$ grunt build
Finally, zip up the dist folder and deploy it to the target host.
Documentation
See guesser and wms-custom-proj for a detailed code walkthrough.
For debugging the application, you can add &debug=true to the URL, which will include all images in the game instead of a random batch. The additional parameter &ix=5 would then jump to the 5th image in the sequence.
Licensing
The source code of this project is licensed under the MIT License.
Schauspielhaus Zürich performances in Wikidata
The goal of the project is to try to ingest all performances of the Schauspielhaus Theater in Zurich held between 1938 and 1968 in Wikidata. In a further step, data from the www.performing-arts.eu Platform, Swiss Theatre Collection and other data providers could be ingested as well.
Data
Tools
- OpenRefine to clean and reconcile data with wikidata
- Wikidata Quick Statements to add new items to wikidata
- Wikidata Quick Statements 2 Beta to add new items to wikidata in batch mode
References
- https://www.wikidata.org/wiki/Wikidata:WikiProject_Performing_arts/Data_sources/CH
- Performing Arts Ontology
- WikiProject Performing arts
- WikiProject Cultural venues
- Wiki Project Cultural events
Methodology
-
load data in OpenRefine
-
Column after column (starting with the easier ones) :
-
reconcile against wikidata
-
manually match entries that matched multiple entries in wikidata
-
find out what items are missing in wikidata
-
load them in wikidata using quick statements (quick statements 2 allow you to retrieve the Q numbers of the newly created items)
-
reconcile again in OpenRefine
-
Results
-
Code to transform csv into quick statements : https://github.com/j4lib/performing-arts/blob/master/create_quick_statements.php
Screenshots
Raw Data

Reconcile in OpenRefine
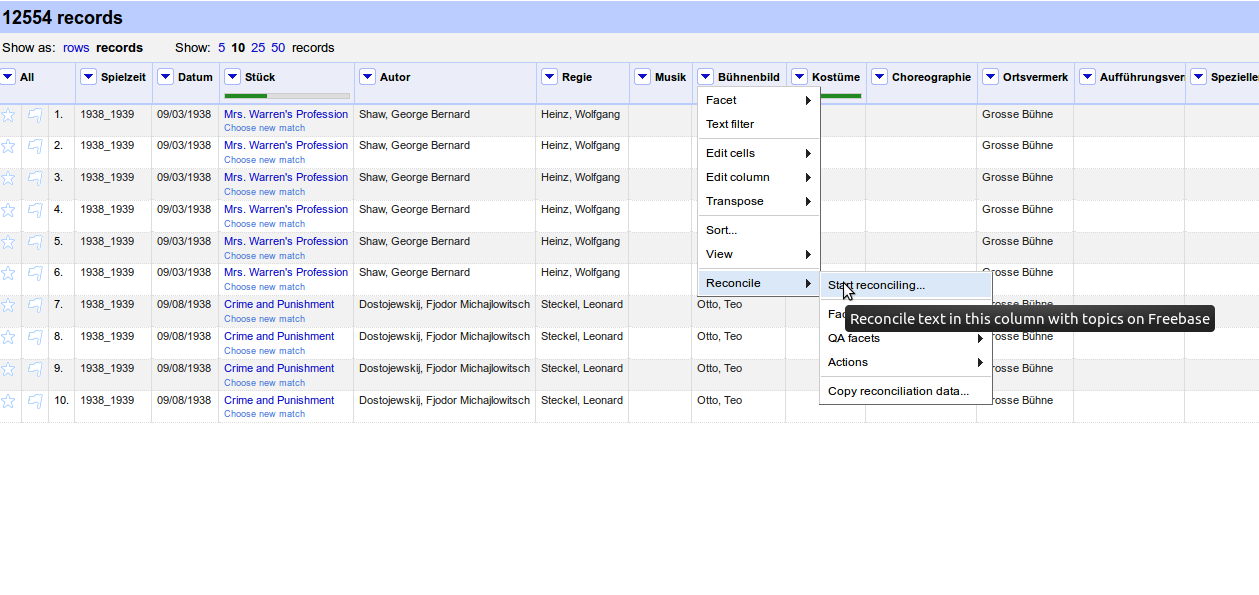
Choose corresponding type
For Work, you can use the author as an additional property
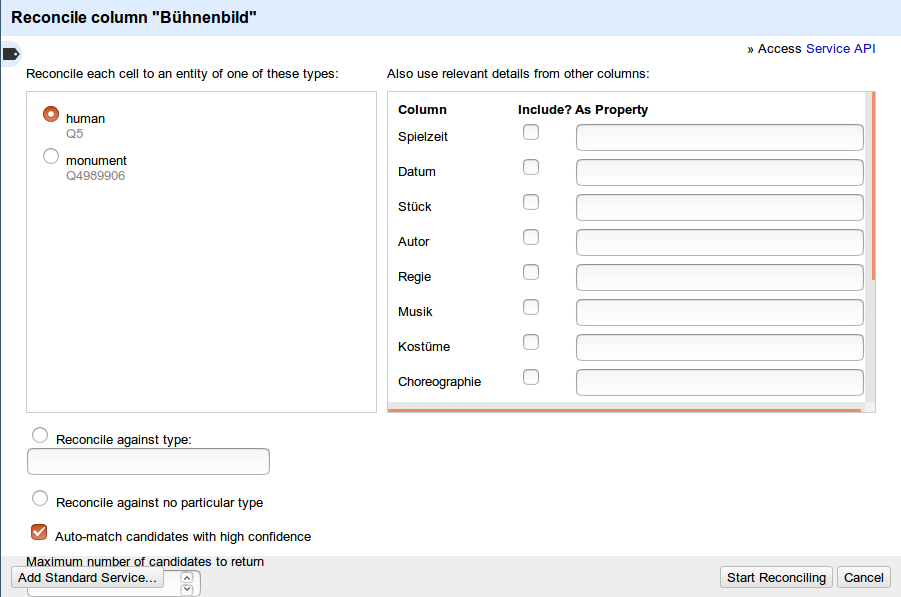
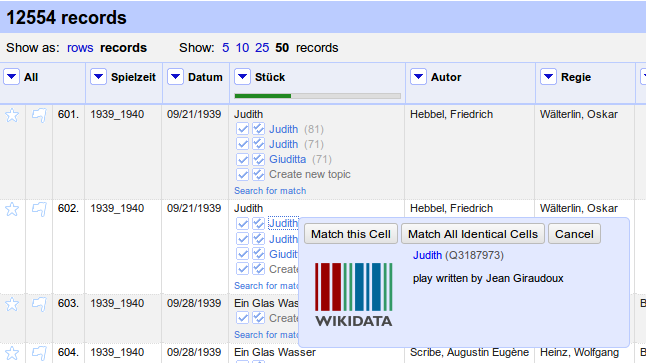
Manually match multiple matches
Import in Wikidata with quick statements
Step 1 
- Len : english label
- P31 : instance of
- Q5 : human
- P106 : occupation
- Q1323191 : costume designer
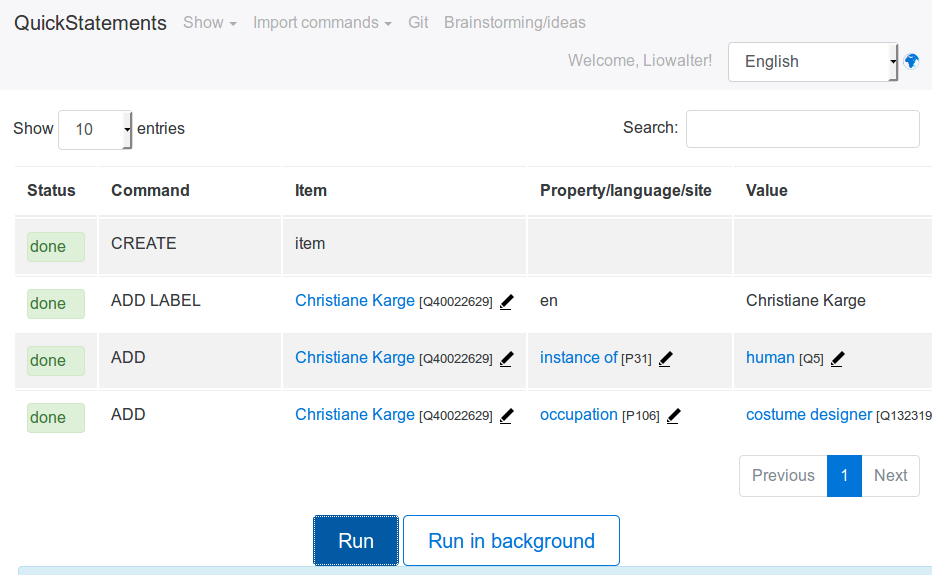
Step 2 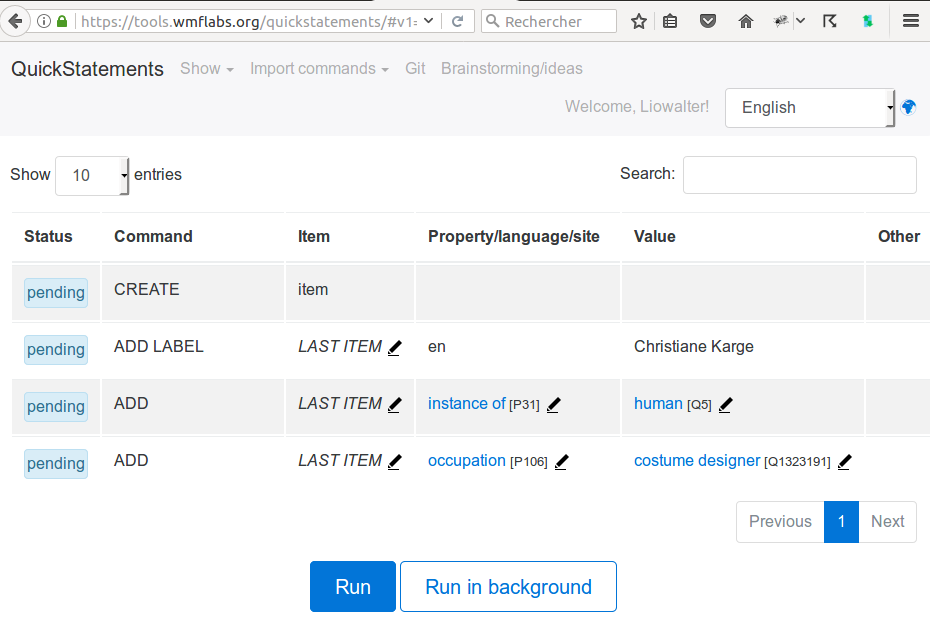
Step 3 (you can get the Q number from there)
Team
- Renate Albrecher
- Julia Beck
- Flor Méchain
- Beat Estermann
- Birk Weiberg
- Lionel Walter
Swiss Video Games Directory
Showcase of the Swiss games scene.
This projects aims at providing a directory of Swiss Video Games and metadata about them.
The directory is a platform to display and promote Swiss Games for publishers, journalists, politicians or potential buyers, as well as a database aimed at the game developers community and scientific researchers.
Our work is the continuation of a project initiated at the 1st Open Data Hackathon in 2015 in Bern by David Stark.
Output
Workflow
- An open spreadsheet contains the data with around 300 entries describing the games.
- Every once in a while, data are exported into the Directory website (not publicly available yet).
- At any moment, game devs or volunteer editors can edit the spreadsheet and add games or correct informations.
Data
The list was created on Aug. 11 2014 by David Javet, game designer and PhD student at UNIL. He then opened it to the Swiss game dev community which collaboratively fed it. At the start of this hackathon, the list was composed of 241 games, starting from 2004. It was turned into an open data set on the opendata.swiss portal by Oleg Lavrovsky.
- Dataset on opendata.swiss portal [from 8 September 2017]
- A copy of the original document
- Current open spreadsheet
Source
Team
- Karine Delvert
- Selim Krichane
- Oleg Lavrovsky
- Frédéric Noyer
- Isaac Pante
- Yannick Rochat
- David Stark (team leader)
- Oliver Waddell
More
David Stark pitching the project.
David Stark testing for the first time in 10 years if his first game can still be played.


Swiss Games Showcase
A website made to show off the work of the growing Swiss computer game scene. The basis of the site is a crowdsourced table of Swiss games.
Additions and Improvements
Want to add a game to this site? Add it to the table! We're especially looking for older games, pre-2010. Any game that was publicly available in some fashion and was created in Switzerland should be included.
Setup
Running the project requires Python, Java, and the requests library. Also, create a "tmp" directory to act as a cache for downloaded images.
Usage
- Re-export the table of Swiss games to TSV and save it as
Swiss Video Games - released-swiss-video-games.tsv. - Invoke
python sitegen2.pyto re-generate the site.
About
This project was created by David Stark for the 1st Swiss Open Cultural Data Hackathon 2015.
It was then extended by David Stark, Karine Delvert, Selim Krichane, Oleg Lavrovsky, Frédéric Noyer, Isaac Pante, Yannick Rochat and Oliver Waddell for the 3rd OpenGLAM Hackathon in 2017.
Wikidata ontology explorer
small website to explore ontologies on Wikidata
A small tool to get a quick feeling of an ontology on Wikidata.
-
Website: https://lucaswerkmeister.github.io/wikidata-ontology-explorer/
-
Source code: https://github.com/lucaswerkmeister/wikidata-ontology-explorer

Data
(None, but hopefully this helps you do stuff with your data :) )
Team
Wikidata ontology explorer
A small website to quickly answer the question “what do items like this typically look like on Wikidata?”
Usage
Open https://lucaswerkmeister.github.io/wikidata-ontology-explorer/.
To explore the ontology of some class, enter the item ID of the class into the “Wikidata class” field.
To explore the ontology of items using some property, select the “by property” radio button and enter the property ID of the property into the “Wikidata property” field.
Click the “Explore” button.
To explore more ontologies, repeat the above steps (but you don’t need to re-open the page).
License
The content of this repository is released under the AGPL v3+ as provided in the LICENSE file that accompanied this code.
By submitting a “pull request” or otherwise contributing to this repository, you agree to license your contribution under the license mentioned above.