
Report
💡 Active projects and challenges as of 21.07.2026 21:00.
Hide text CSV Data Package Print
Dadabot
Animation in the spirit of dada poetry
The computer produces animations. Dada! All your artworks are belong to us. We build the parameters, you watch the animations. Words, images, collide together into ever changing, non-random, pseudo-random, deliberately unpredictable tensile moments of social media amusement. Yay!
For this first prototype we used Walter Serner's Text "Letzte Lockerung -- Manifest Dada" as a source. This text is consequently reconfigured, rewritten and thereby reinterpreted by the means of machine learning using "char-rnm".
Images in the public domain snatched out of the collection "Wandervögel" from the Schweizerische Sozialarchiv.
Your instant piece of art
By sending something to the Twitter account @a__da___d, you get a piece of animated dada back. Smile and enjoy.
Data
- Images are taken from the collection Wandervögel from the Schweizerische Sozialarchiv
- Text Walter Serner Letzte Lockerung - Manifest Dada
- Tool char-rnn
Team
dadatalekom
a mindful #glamhack brought to you by SODA/camp
based on Zulko/gizeh and karan/slashgif
deployment
Copy config-sample.py to config.py and fill in the data.
sudo apt-get install python-numpy
virtualenv env --system-site-packages
. env/bin/activate
pip install -r requirements.txt
python bot.py
Dodis Goes Hackathon
Wir arbeiten mit den Daten zu den Dokumenten von 1848-1975 aus der Datenbank Dodis und nutzen hierfür Nodegoat.




Animation (mit click öffnen):
Data
Team
- Christof Arnosti
- Amandine Cabrio
- Lena Heizmann
- Christiane Sibille
GlamHack Clip 2016
Short clip edited to document the GLAMHack 2016, featuring short interviews with hackathon participants that we recorded on site and additional material from the Open Cultural Data Sets made available for the hackathon.
Data
Music - Public Domain Music Recordings and Metadata / Swiss Foundation Public Domain
- Amilcare Ponchielli (1834-1886), La Gioconda, Dance of the hours (part 2), recorded in Manchester, 29. Juli 1941
- Joseph Haydn, Trumpet Concerto in E Flat, recorded on the 19. Juni 1946
Aerial Photographs by Eduard Spelterini / Swiss National Library
- Eduard Spelterini, Basel between 1893 and 1923. See picture.
- Eduard Spelterini, Basel between 1893 and 1902. See picture.
Bilder 1945-1973 / Dodis
- 1945: Ankunft jüdischer Flüchtlinge
- 1945: Flüchtlinge an der Grenze
Team
- Jan Baumann (infoclio.ch)
- Enrico Natale (infoclio.ch)
GLAM RDF Search Portal
Semweb provides an application using RDF data coming from project glam_rdf_data_online. This data contains RDFized collections from
- Davit Mittelholzer collection/ E-PICS (ETH-Zürich)\
- Gugelmann collection / Swiss National Library\
- FOTOS.ch fotographs data collection / https://www2.foto-ch.ch\
- Openglam inventory lists (datahub.io)
Access: https://ch.semweb.ch:8439/SemwebLODSearchPortal/APP.jsp
This search portal has an entry page containing a tag cloud and a search field. From here the user can insert her/his search text or pick up a tag from the tag cloud. The application starts showing results from RDF queries based on glam_rdf_data_online.
The search portal is intended as demonstrator search portal which permits to explore linked data coming from a remote RDF Store in a ludic way.
Each search delivers three layers of information:
i) Facets in which the search term appears
ii) Data inside each facet
iii) Thesaurus data coming from GETTY Thesaurus for Art and Architecture
More in detail
i) The facets shown as a result of each search denote 1:1 the RDF properties which addresses text literals containing the search term. The name of some of these properties were translated to English names, others are default as they come from RDF data.
ii) Object data are listed with icons. Where a picture is existent / could be found, it is served, otherwise a static icon is shown (some picture are retrieved from the RDF material, others via web). Clicking on one icon shows the details for the corresponding entity. For some (few) entities where a combination waas possible, like categories inside an EPIC entity, clicking on that category starts a search on elements linking to that category. Items are navigable through arrows.
iii) Thesaurus data are queried and collected and shown using the SKOS model. Thesaurus data are useful for both expanding or restricting a search. Theaurus data are shown following the SKOS model in broader/narrower/related concepts - these concept are named here "semantic facets". After retrieval of thesaurus data, an agent calculates in advance the matches on the current RDF material in case a semantic facet be clicked (for search). The thesaurus search - as well as the agent search - are perfomed as well using SPARQL queries.
Adding a data source is quite easy
Adding a further (RDF) data source is very easy. The application is not yet a metaframework accepting any source but with some effort can be enhanced to accept a new data source "on-the-fly".
Enhancements
Since the application is a prototype, it needs refinement. For instance in result ranking, stronger Interlinking and maybe on the efficiency levels.
Further screenshots
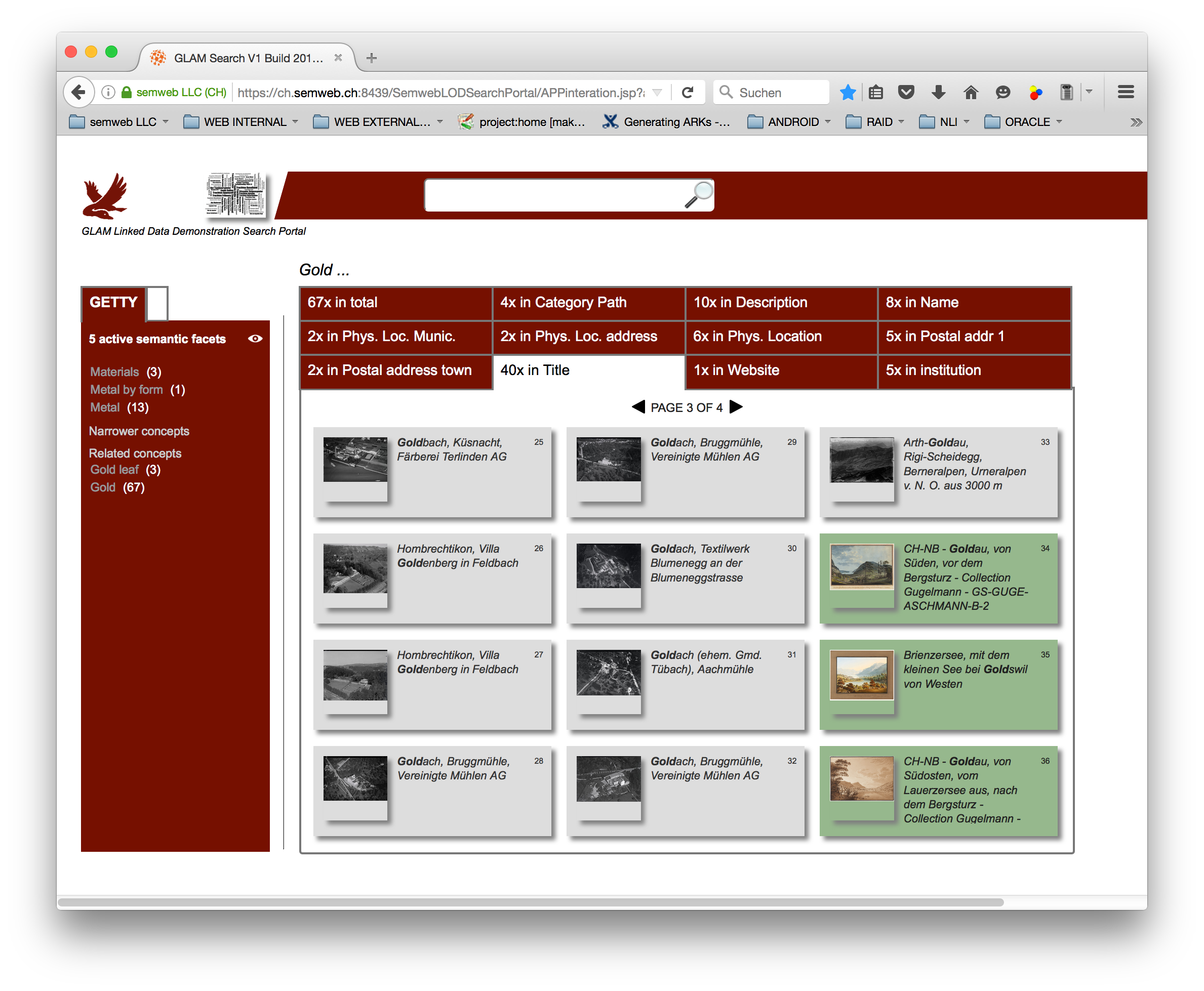 Picture 2: GLAM Demonstrator Search Portal - Searching 4 gold ...
Picture 2: GLAM Demonstrator Search Portal - Searching 4 gold ...
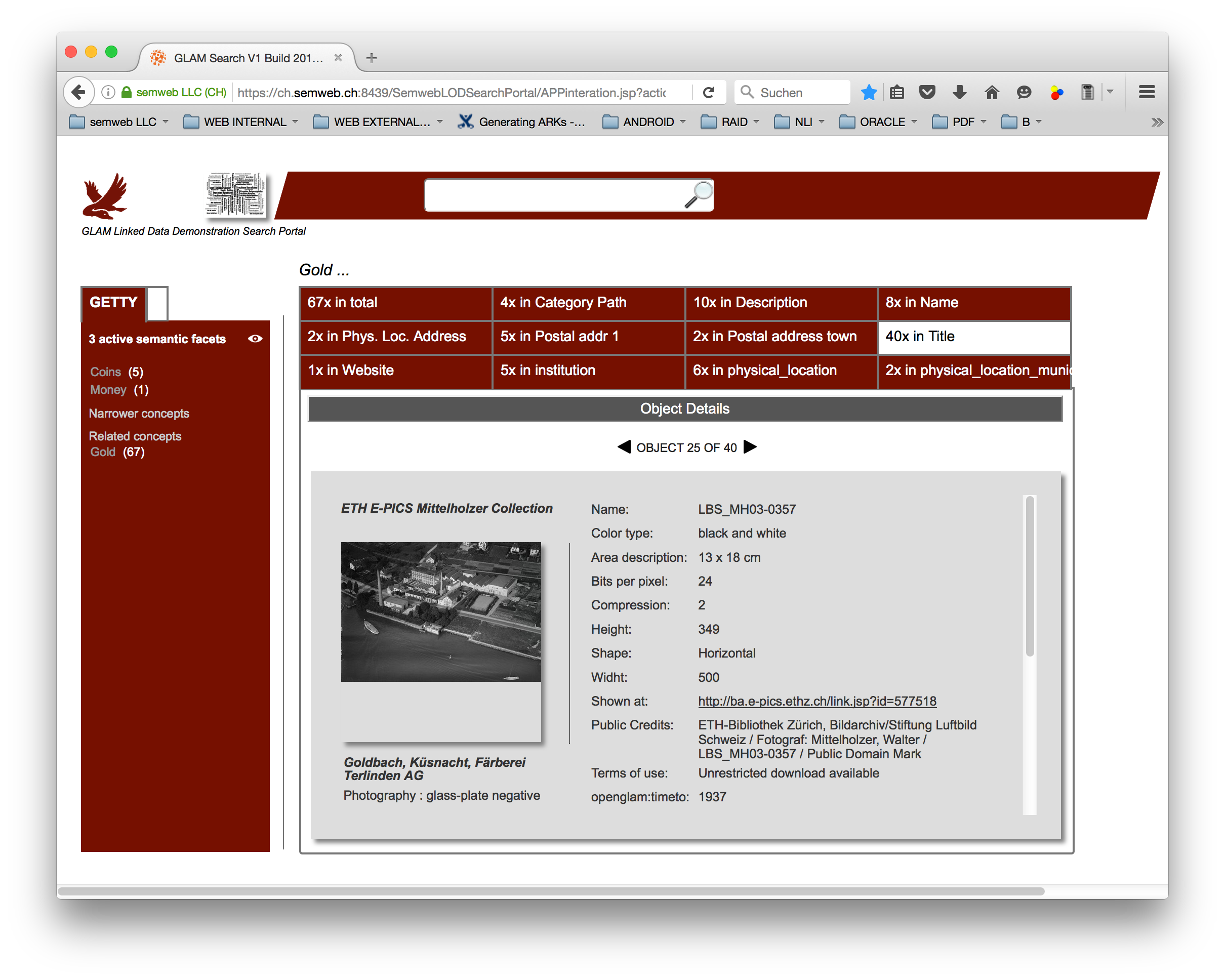 Picture 3a: GLAM Demonstrator Search Portal - Detail on one EPIC entity ...
Picture 3a: GLAM Demonstrator Search Portal - Detail on one EPIC entity ...
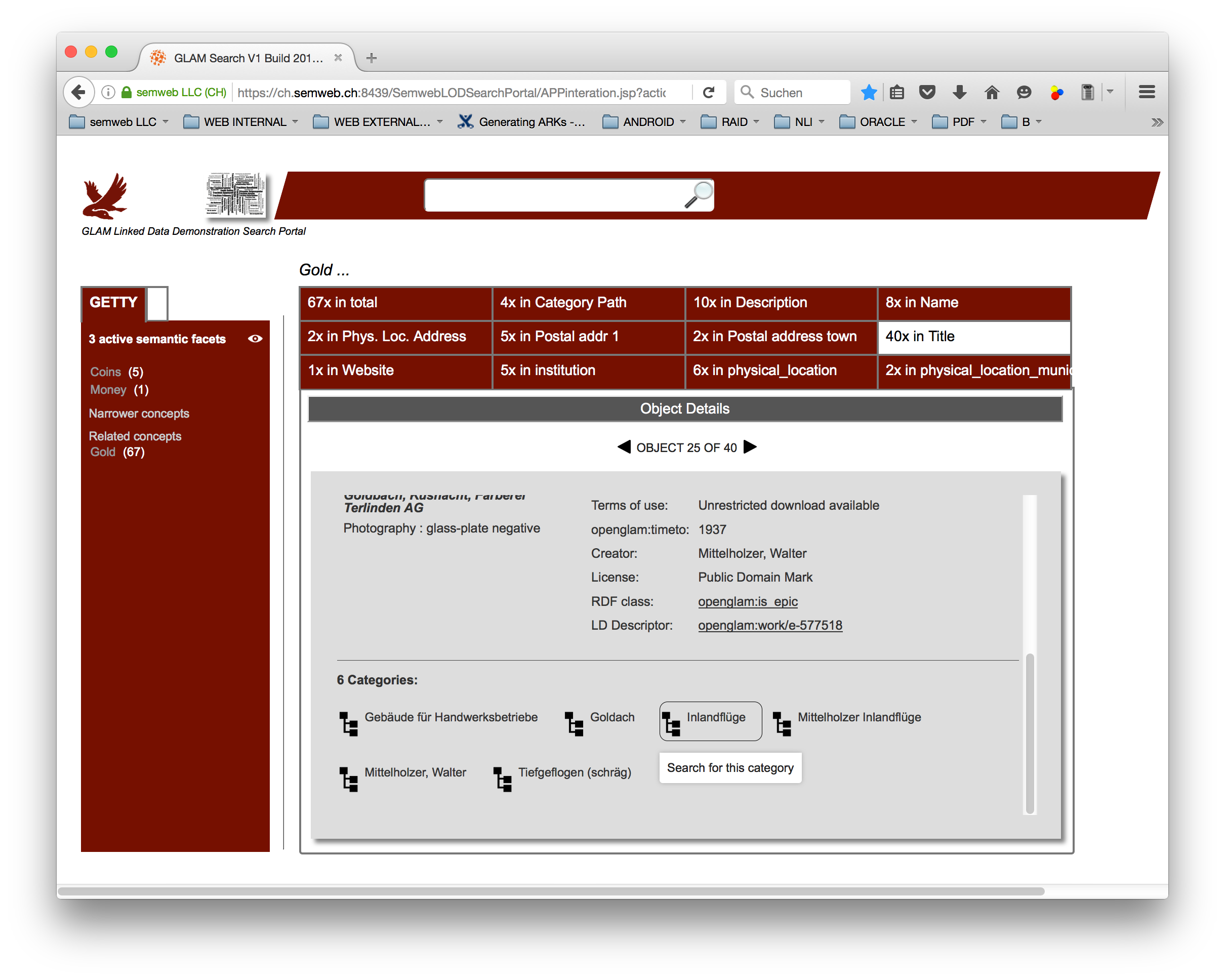 Picture 3b: GLAM Demonstrator Search Portal - Detail on same EPIC entity showing navigable categories
Picture 3b: GLAM Demonstrator Search Portal - Detail on same EPIC entity showing navigable categories
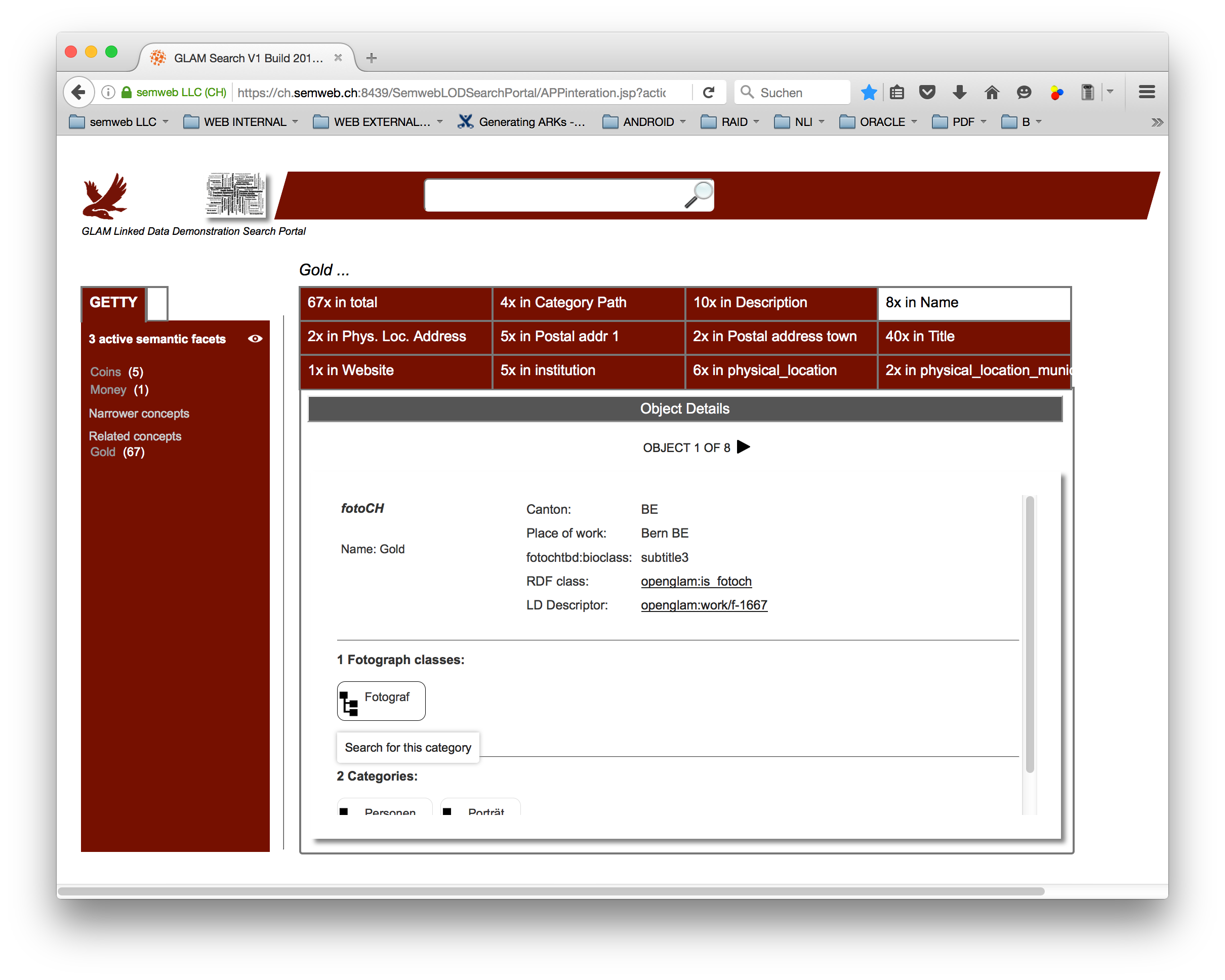 Picture 4a: GLAM Demonstrator Search Portal - Detail FOTO.ch Entity
Picture 4a: GLAM Demonstrator Search Portal - Detail FOTO.ch Entity
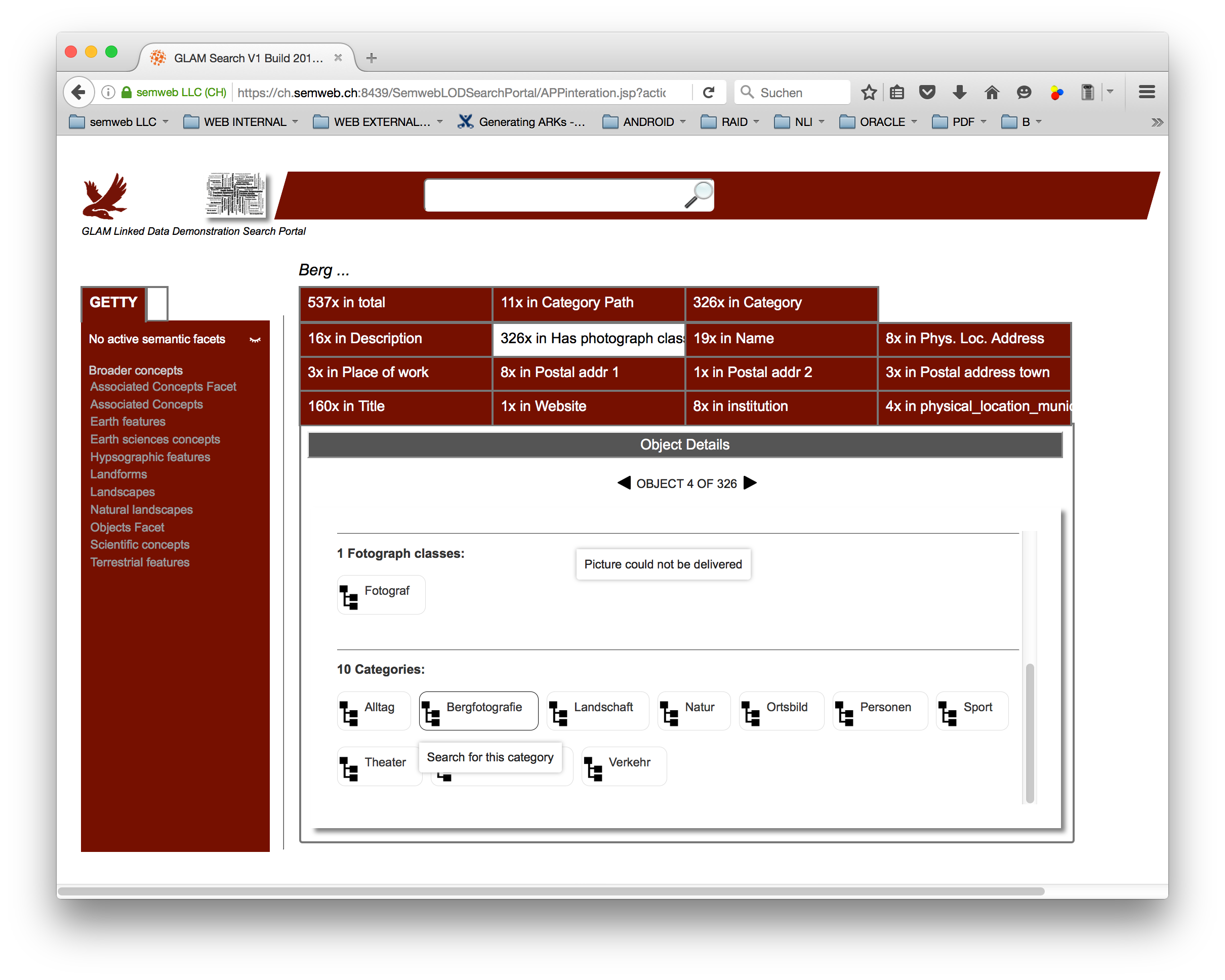 Picture 4b: GLAM Demonstrator Search Portal - Detail FOTO.ch Entity on categories
Picture 4b: GLAM Demonstrator Search Portal - Detail FOTO.ch Entity on categories
Data
Data from namespage "openglam2" in [[project:glam_rdf_data_online]]
Team
Historical Dictionary of Switzerland
(HDS) Out of the Box
The Historical Dictionary of Switzerland (HDS) is an academic reference work which documents the most important topics and objects of Swiss history from prehistory up to the present.
The HDS digital edition comprises about 36.000 articles organized in 4 main headword groups:\
- Biographies,\
- Families,\
- Geographical entities and\
- Thematical contributions.
Beyond the encyclopaedic description of entities/concepts, each article contains references to primary and secondary sources which supported authors when writing articles.
Data
We have the following data:
- metadata information about HDS articles Historical Dictionary of Switzerland comprising:
- bibliographic references of HDS articles
- article titles
- Le Temps digital archive for the year 1914
Goals
Our projects revolve around linking the HDS to external data and aim at:
- Entity linking towards HDS
The objective is to link named entity mentions discovered in historical Swiss newspapers to their correspondant HDS articles. - Exploring reference citation of HDS articles
The objective is to reconcile HDS bibliographic data contained in articles with SwissBib.
Named Entity Recognition
We used web-services to annotate text with named entities:\
- Dandelion\
- Alchemy\
- OpenCalais

Named entity mentions (persons and places) are matched against entity labels of HDS entries and directly linked when only one HDS entry exists.
Further developments would includes:\
- handling name variants, e.g. 'W.A. Mozart' or 'Mozart' should match 'Wolfgang Amadeus Mozart' .\
- real disambiguation by comparing the newspaper article context with the HDS article context (a first simple similarity could be tf-idf based)\
- working with a more refined NER output which comprises information about name components (first, middle,last names)
Some statistics
In the 23.622 articles of the year 1914 in «Le Temps digital archive» we linked 90.603 entities pointing to 1.417 articles of the «Historical Dictionary of Switzerland».

Web Interface
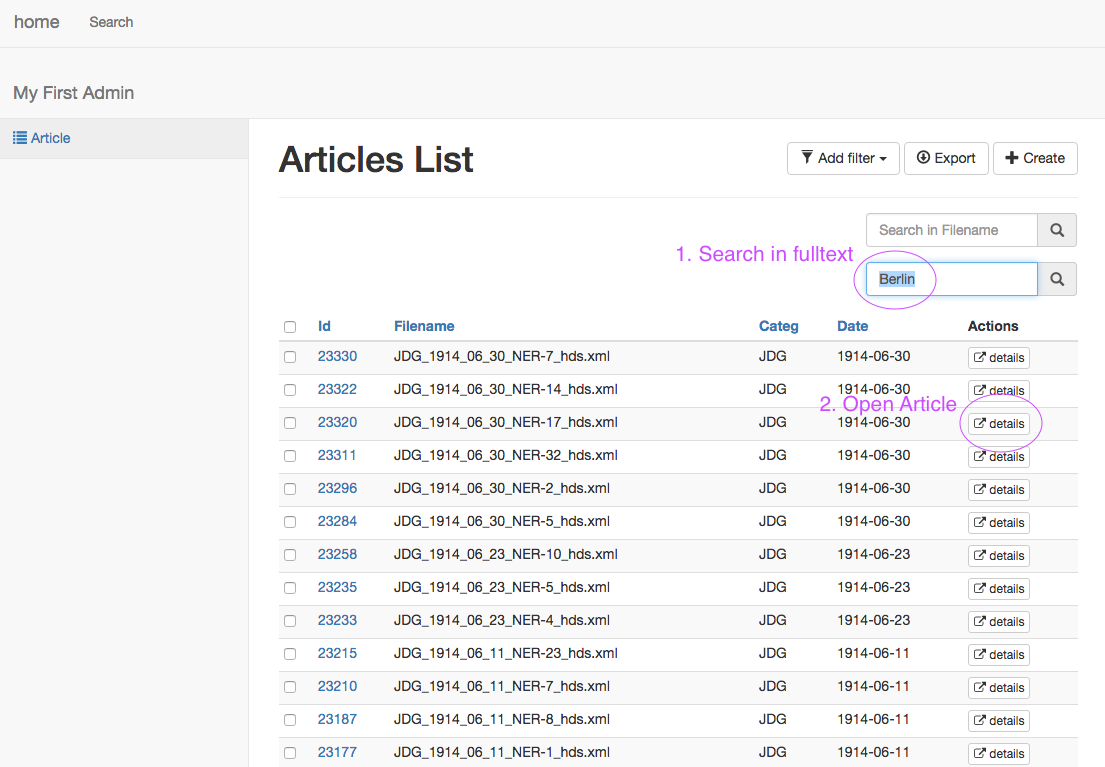
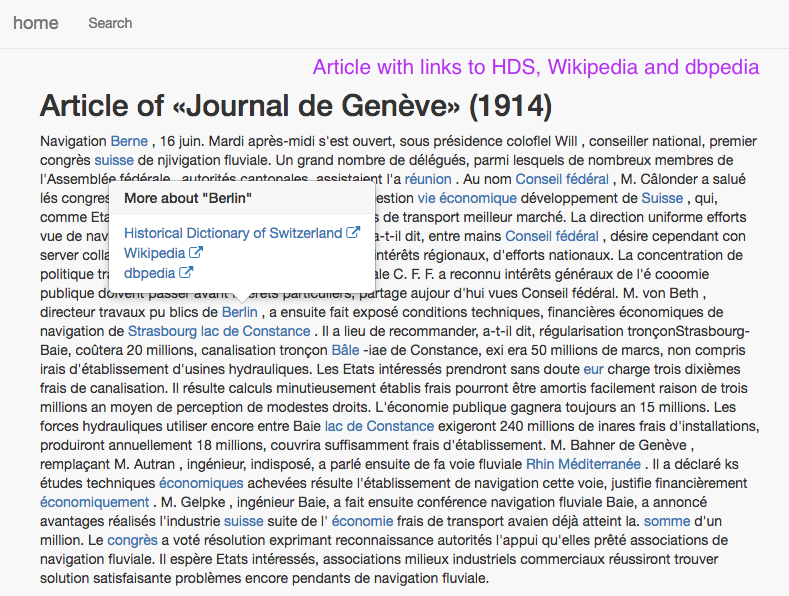
We developed a simple web interface for searching in the corpus and displaying the texts with the links.
It consists of 3 views:
1. Home
2. Search
3. Article with links to HDS, Wikipedia and dbpedia
Further works
Further works would include:\
- evaluate and improve method.\
- apply the method to the Historical Dictionary of Switzerland itself for internal linking.
Bibliographic enrichment
We work on the list of references in all articles of the HDS, with three goals:
- Finding all the sources which are cited in the HDS (several sources are cited multiple times) ;
- Link all the sources with the SwissBib catalog, if possible ;
- Interactively explore the citation network of the HDS.
The dataset comes from the HDS metadata. It contains lists of references in every HDS article:

Result of source disambiguation and look-up into SwissBib:
Bibliographic coupling network of the HDS articles (giant component). In Bibliographic coupling two articles are connected if they cite the same source at least once. Biographies (white), Places (green), Families (blue) and Topics (red):
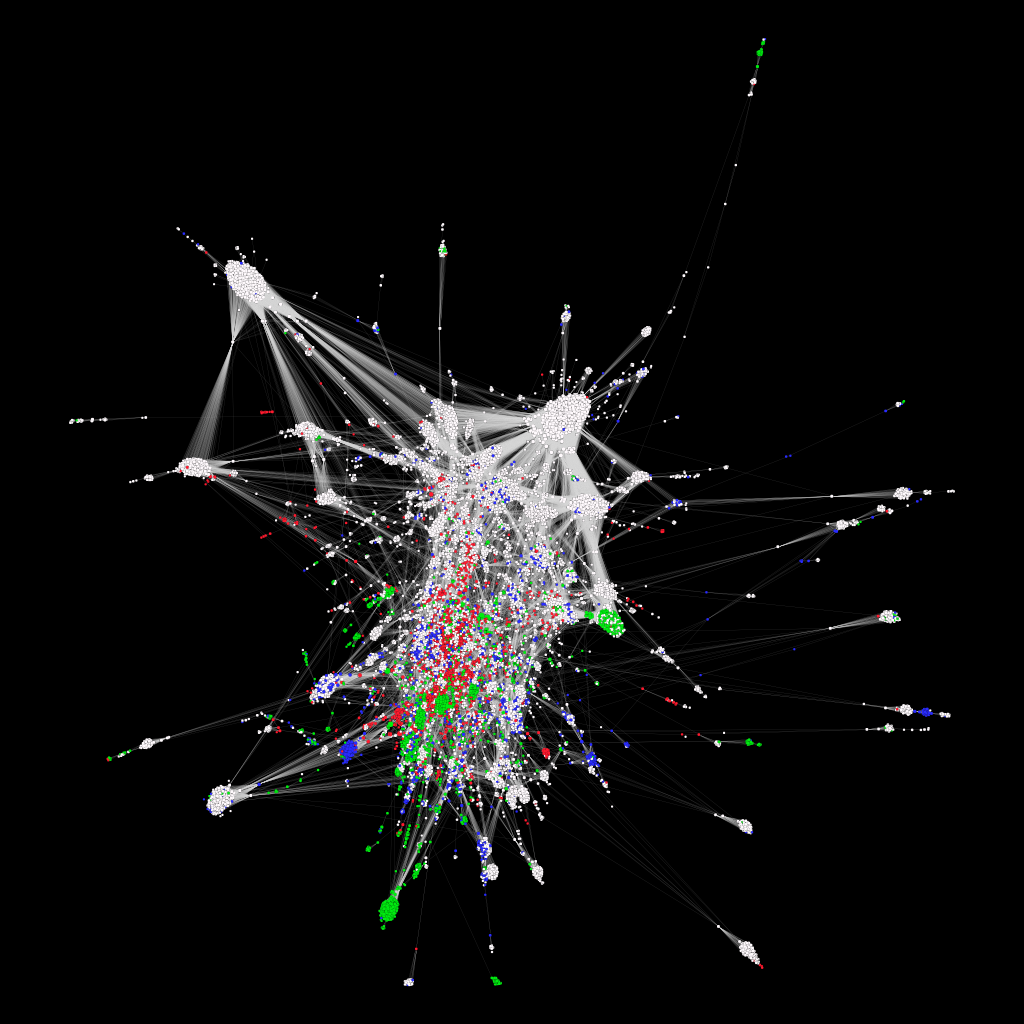
Ci-citation network of the HDS sources (giant component of degree > 15). In co-citation networks, two sources are connected if they are cited by one or more articles together. Publications (white), Works of the subject of an article (green), Archival sources (cyan) and Critical editions (grey):

Exploring bibliographic enrichment with OpenRefine
Bibliographic data in the HDS citations is unfortunately not structured. There is no logical separation between work title, publication year, page numbers, etc. other than typographical convention. Furthermore, many citations contain abbreviations. Using OpenRefine to explore the dataset, multiple approaches were attempted to query the swissbib SRU API using unstructured citation data.
Examples of unstructured data issues
- L'oro bruno - Cioccolato e cioccolatieri delle terre ticinesi, Ausstellungskat. Lottigna, 2007 - Elements of the citation are sometimes divided by commas (,) but there is no fixed rule. In this case, the first comma separates the title from an object type. Another comma separates the place of publication with the publication year.
- A. Niederer, «Vergleichende Bemerkungen zur ethnolog. und zur volkskundl. Arbeitsweise», in Beitr. zur E. der Schweiz 4, 1980, 1-25 - This citation mentions an article within a collection, the commas separate publication year and page numbers.
- La visite des églises du diocèse de L. en 1453, hg. von A. Wildermann et al., 1993 - The subject of the dictionary entry is often abbreviated in the related citations. In this example, "L." stands for Lausanne, because the citation comes from the dictionary entry for Lausanne.
- Stat. Jb. des Kt. L., 2002- - In this example, "L." stands for Luzern. The other abbreviations are standard and can be resolved using the dictionary's list of abbreviations.
OpenRefine workflow
After several attempts, it was established that combining several keywords from the reference title with the authors (without initials) produced the best results for querying swissbib. The following GREL expression can be applied to the OpenRefine column (using Edit column → Add column based on this column) that contains the contents of the
join(with(value.split(" "),a,forEach(a,v,v.chomp(",").match(/([a-zA-Z\u00C0-\u017F-']{4,}|\d{4})/)[0]))," ")+" "+forNonBlank(cells["NOTICE - AUT"],v,v.value.match(/(.* |)(\w{2,})/)[1]," ")
Note that the above expression combines the
Swissbib queries can return Dublin Core, MARC XML or MARC in JSON format. Dublin core is the easiest to manipulate, but unfortunately it does not contain the entirety of the returned record. To access the full record, it is necessary to use either MARC XML or MARC JSON.
To query swissbib and return Dublin Core, use (using Edit column → Add column by fetching URLs):
replace("http://sru.swissbib.ch/sru/search/defaultdb?query=+dc.anywhere+%3D+{QUERY}&operation=searchRetrieve&recordSchema=info%3Asru%2Fschema%2F1%2Fdc-v1.1-light&maximumRecords=10&startRecord=0&recordPacking=XML&availableDBs=defaultdb&sortKeys=Submit+query", "{QUERY}", escape(replace(value,/[\.\']/,""),'url'))
To get MARC XML, use
replace("http://sru.swissbib.ch/sru/search/defaultdb?query=+dc.anywhere+%3D+{QUERY}&operation=searchRetrieve&recordSchema=info%3Asrw%2Fschema%2F1%2Fmarcxml-v1.1-light&maximumRecords=10&startRecord=0&recordPacking=XML&availableDBs=defaultdb&sortKeys=Submit+query", "{QUERY}", escape(replace(value,/[\.\']/,""),'url'))
To get MARC JSON, use
replace("http://sru.swissbib.ch/sru/search/defaultdb?query=+dc.anywhere+%3D+{QUERY}&operation=searchRetrieve&recordSchema=info%3Asru%2Fschema%2Fjson&maximumRecords=10&startRecord=0&recordPacking=XML&availableDBs=defaultdb&sortKeys=Submit+query", "{QUERY}", escape(replace(value,/[\.\']/,""),'url'))
Using either of these queries seems to be returning good results. The returned data must be parsed to extract the required fields, for example the following GREL expression extracts the Title from the swissbib data when it is returned as Dublin Core:
if(value.parseHtml().select("numberOfRecords")[0].htmlText().toNumber()>0,value.parseHtml().select("recordData")[0].select("dc|title")[0].htmlText(), null)
All the above operations can be reproduced on an OpenRefine project containing DHS citation data by using this operations JSON expression. See "Replaying operations" in the OpenRefine documentation for more details on how to apply this to an existing project.
Link back to swissbib
Using the above queries, it is possible to receive the swissbib record ID that corresponds to a citation entry. Unfortunately, those record IDs are computed anew every time the swissbib dataset is processed. This ID therefore cannot be used to uniquely identify a record. Instead, it is necessary to use one of the source catalogue ID.
For example, looking at the following returned result (in MARC XML format):
<record>
<recordSchema>info:srw/schema/1/marcxml-v1.1</recordSchema>
<recordPacking>xml</recordPacking>
<recordData>
<record xmlns:xs="http://www.w3.org/2001/XMLSchema">
<leader>caa a22 4500</leader>
<controlfield tag="001">215650557</controlfield>
<controlfield tag="003">CHVBK</controlfield>
<controlfield tag="005">20130812154822.0</controlfield>
<controlfield tag="008">940629s1994 sz 00 fre d</controlfield>
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(RERO)1875002</subfield>
</datafield>
(...)
<datafield tag="100" ind1="1" ind2=" ">
<subfield code="a">Robert</subfield>
<subfield code="D">Olivier</subfield>
<subfield code="c">historien</subfield>
</datafield>
<datafield tag="245" ind1="1" ind2="3">
<subfield code="a">La fabrication de la bière à Lausanne</subfield>
<subfield code="b">la brasserie du Vallon</subfield>
<subfield code="c">par Olivier Robert</subfield>
</datafield>
(...)
</record>
</recordData>
<recordPosition>0</recordPosition>
</record>
we find that this record has the internal swissbib ID of 215650557 but we know we cannot use it to retrieve this record in the future, since it can change. Instead, we have to use the ID of the source catalogue, in this case RERO, found in the MARC field 035$a:
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">(RERO)1875002</subfield>
</datafield>
A link back to swissbib can be constructed as
https://www.swissbib.ch/Search/Results?lookfor=RERO1875002&type=AllFields
(note that the parentheses around "RERO" have to be removed for the search URL to work).
Further works
This is only the first step of a more general work inside the HDS:\
- identify precisely each notice in an article (ID attribute to generate)\
- collect references with a separation by language\
- clean and refine the collected data\
- setup a querying workflow that keeps the ID of the matched target in a reference catalog\
- replace each matching occurence in the HDS article by a reference to an external catalog
Team
- Pierre-Marie Aubertel
- Francesco Beretta
- Giovanni Colavizza
- Maud Ehrmann
- Thomas Guignard
- Jonas Schneider
Historical maps
The group discussed the usage of historical maps and geodata using the Wikimedia environment. Out of the discussion we decided to work on 4 learning items and one small hack.
The learning items are:
- The workflow for historical maps - the Wikimaps workflow
- Wikidata 101
- Public artworks database in Sweden - using Wikidata for storing the data
- Mapping maps metadata to Wikidata: Transitioning from the map template to storing map metadata in Wikidata. Sum of all maps?
The small hack is:
- Creating a 3D gaming environment in Cities Skylines based on data from a historical map.
Data
This hack is based on an experimentation to map a demolished and rebuilt part of Helsinki. In DHH16, a Digital Humanities hackathon in Helsinki this May, the goal was to create a historical street view. The source aerial image was georeferenced with Wikimaps Warper, traced with OpenHistoricalMap, historical maps from the Finna aggregator were georeferenced with the help of the Geosetter program and finally uploaded to Mapillary for the final street view experiment.
The Small Hack - Results
Our goal has been to recreate the historical area of Helsinki in a modern game engine provided by Cities: Skylines (Developer: Colossal Order). This game provides a built-in map editor which is able to read heightmaps (DEM) to rearrange the terrain according to it. Though there are some limits to it: The heightmap has to have an exact size of 1081x1081px in order to be able to be translated to the game's terrain.
To integrate streets and railways into the landscape, we tried to use an already existing modification for Cities: Skylines which can be found in the Steam Workshop: Cimtographer by emf. Given the coordinates of the bounding box for the terrain, it is supposed to read out the geometrical information of OpenStreetMap. A working solution would be amazing, as one would not only be able to read out information of OSM, but also from OpenHistoricalMap, thus being able to recreate historical places. Unfortunately, the algorithm is not working that properly - though we were able to create and document some amazing "street art".
Another potential way of how to recreate the structure of the cities might be to create an aerial image overlay and redraw the streets and houses manually. Of course, this would mean an enormous manual work.
Further work can be done regarding the actual buildings. Cities: Skylines provides the opportunity to mod the original meshes and textures to bring in your very own structures. It might be possible to create historical buildings as well. However, one has to think about the proper resolution of this work. It might also be an interesting task to figure out how to create low resolution meshes out of historical images.
Team
- Susanna Ånäs
- Karin Tonollo
- Elena Scepankova
- Stephan Unter
Kirchenarchive
Datenbank Kirchenarchive Schweiz (AGGA - VSA)

Data description: Archival description of the fonds of selected ecclesiastical archives in Switzerland (christian churches - parishes, monasteries, missions, other religions are included in the ecumenical sense); reference data only - full text information has to be organized accordingly; data dictionary is in place; Web site is done in php. See full description in german
Data ownership: Working Group of ecclesiastical archivists (AGGA) WITHIN the Swiss Association of archivists (VSA)
Project goal: Dissemenination of catalogued data for a broader scope in an open format (possibly LOD) for the public, mainly for historical research and theology. In the future, primary data could be interlinked either (partially from existing repositories like [[http://www.e-codices.unifr.ch/de|eCodices] or others ] In the future full text data (e.g. minutes) could be embedded.
Project steps:
- Extracting raw data from DB: mySQL dump (approx. 1000 datasets) - delivered by Admin: Erich Schneider (ZH)
- Reorganize / restructure and index data; reload on a dedicated page (site)
- Dissemination / publication according to Open GLAM principles: index of Swiss cultural heritage data; portals to be selected (Swiss heritage institutions); as a pre-condition all "Archivträger" (owning organisations) have to approve the free publication of their metadata for GLAM purposes first.
- This last step shall be done under a CC-0 licence (Creative Commons)
JH
Data
to be processed.
Team
- jhagmann-at-gmail.com - ideator: Jürg Hagmann (member of the working group AGGA)
- C.G.
- Supported by Oleg
2018
- Jürg Hagmann
- Silvan Heller
Linked Open Theatre Data
The goal of the project is to publish Swiss Theatre Data of the Swiss Theatre Collection in RDF format and to expose it through a SPARQL endpoint.
In a further step, data from the www.performing-arts.eu Platform and other data providers could be ingested as well.
Some of the data will also be ingested into Wikidata:
Ontology
Data
-
Data from the www.performing-arts.eu Portal
Team
- Christian Schneeberger
- René Vielgut
- Julia Beck
- Adrian Gschwend
- beat_estermann
Manesse Gammon
A medieval game: Play against «Herrn Gœli»
The Codex Manesse, or «Große Heidelberger Liederhandschrift», is an outstanding source of Middle High German Minnesang, a book of songs and poetry the main body of which was written and illustrated between 1250 and 1300 in Zürich, Switzerland. The Codex, produced for the Manesse family, is one of the most beautifully illustrated German manuscripts in history.
The Codex Manesse is an anthology of the works of about 135 Minnesingers of the mid 12th to early 14th century. For each poet, a portrait is shown, followed by the text of their works. The entries are ordered by the social status of the poets, starting with the Holy Roman Emperor Heinrich VI, the kings Konrad IV and Wenzeslaus II, down through dukes, counts and knights, to the commoners.

Page 262v, entitled «Herr Gœli», is named after a member of the Golin family originating from Badenweiler, Germany. «Herr Gœli» may have been identified either as Konrad Golin (or his nephew Diethelm) who were high ranked clergymen in 13th century Basel. The illustration, which is followed by four songs, shows «Herrn Gœli» and a friend playing a game of Backgammon (at that time referred to as «Pasch», «Puff», «Tricktrack», or «Wurfzabel»). The game is in full swing, and the players argue about a specific move.

Join in and start playing a game of backgammon against «Herrn Gœli». But watch out: «Herr Gœli» speaks Middle High German, and despite his respectable age he is quite lucky with the dice!
Instructions
You control the white stones. The object of the game is to move all your pieces from the top-left corner of the board clockwise to the bottom-left corner and then off the board, while your opponent does the same in the opposite direction. Click on the dice to roll, click on a stone to select it, and again on a game space to move it. Each die result tells you how far you can move one piece, so if you roll a five and a three, you can move one piece five spaces, and another three spaces. Or, you can move the same piece three, then five spaces (or vice versa). Rolling doubles allows you to make four moves instead of two.
Note that you can't move to spaces occupied by two or more of your opponent's pieces, and a single piece without at least another ally is vulnerable to being captured. Therefore it's important to try to keep two or more of your pieces on a space at any time. The strategy comes from attempting to block or capture your opponent's pieces while advancing your own quickly enough to clear the board first.
And don't worry if you don't understand what «Herr Gœli» ist telling you in Middle High German: Point your mouse to his message to get a translation into modern English.
Updates
- 2016/07/01 v1.0: Index page, basic game engine
- 2016/07/02 v1.1: Translation into Middle High German, responsive design
- 2016/07/04 v1.11: Minor bug fixes
Data
- Universitätsbibliothek Heidelberg: Der Codex Manesse und die Entdeckung der Liebe
- Universitätsbibliothek Heidelberg: Große Heidelberger Liederhandschrift -- Cod. Pal. germ. 848 (Codex Manesse)
- Wikimedia Commons: Codex Manesse
- Historisches Lexikon der Schweiz: Manessische Handschrift
- Historisches Lexikon der Schweiz: Baden, von
- Wörterbuchnetz: Mittelhochdeutsches Handwörterbuch von Matthias Lexer
Author
- Prof. Thomas Weibel, Thomas Weibel Multi & Media
Online SPARQL endpoint with RDF data
Semweb provides a SPARQL Endpoint as a basis to build Linked Data Applications.
Access the SPARQL endpoint at https://ch.semweb.ch:8431/bigdata/#query (no credentials needed)
Note: This SPARQL endpoint will be available until July 31st 2016. After that date, the endpoint will be put offline. It will still be used as a basis for the glamsearchportal project demo.
To be used in two ways:
-
Query RDF Data from the repositories "openglam" and "openglam2" directly or via REST
-
Add your new respository namespace (please do not delete other namespaces than yours!), upload and use RDF Data
Notes:
a) The namespace "openglam2" is also the basis for another project - GLAMSearchPortal - so please do not change data here.
b) Nevertheless you might query data from namespace openglam2. This namespace contains RDFized data from:\
- David Mittelholzer (Fotograph) - collection from EPIC (ETH Zürich)\
- Gugelmann\
- Fotographs data from https://www2.foto-ch.ch/#/home\
- Openglam Inventory data from datahub.io
Data
Under the link https://ch.semweb.ch:8431/bigdata/#query you access a BLAZEGRAPH Workbench where you can * Add some repository * Add some data (please each one in her/his repository) * Query the data interactively or via REST - no credentials needed
Team
Performing Arts Ontology
The goal of the project is to develop an ontology for the performing arts domain that allows to describe the holdings of the Swiss Archives for the Performing Arts (formerly Swiss Theatre Collection and Swiss Dance Collection) and other performing arts related holdings, such as the holdings represented on the Performing Arts Portal of the Specialized Information Services for the Performing Arts (Goethe University Frankfurt).
See also: Project "Linked Open Theatre Data"
Data
- Swiss Theatre Metadata (on datahub.io)
- Repertoire des Schauspielhauses Zürich (Mapping File)
- Data from the www.performing-arts.eu Portal
Project Outputs
2017:
- Draft Version of the Swiss Performing Arts Ontology (Pre-Release, 24 May 2017)
2016:
- Initial Data Modelling Experiments: Swiss Performing Arts Vocabulary (deprecated)
Resources
Team
- Christian Schneeberger
- Birk Weiberg
- René Vielgut (2016)
- Julia Beck
- Adrian Gschwend
- beat_estermann
SFA-Metadata at EEXCESS
(swiss federal state archives)
The goal of our „hack" is to reuse existing search and visualization tools for dedicated datasets provided by the swiss federal state archives.
The project EEXCESS (EU funded research project, www.eexcess.eu) has the vision to unfold the treasure of cultural, educational and scientific long-tail content for the benefit of all users. In this context the project realized different software components to connect databases, providing means for both automated (recommender engine) and active search queries and a bunch of visualization tools to access the results.
The federal swiss state archives hosts a huge variety of digitized objects. We aim at realizing a dedicated connection of that data with the EEXCESS infrastructure (using a google chrome extension) and thus find out, whether different ways of visualizations can support intuitive access to the data (e.g. Creation of virtual landscapes from socia-economic data, browse through historical photographs by using timelines or maps etc.).
Let's keep fingers crossed ...



Data
- https://opendata.swiss/en/dataset/swiss-archives-archive-database-of-the-swiss-federal-archives
- http://eexcess.eu
Team
- Louis Gantner
- Daniel Hess
- Marco Majoleth
- André Ourednik
- Jörg Schlötterer
sprichort
an application which lets users travel in time.
sprichort is an application which lets users travel in time. The basis are a map and historical photographs like Spelterini's photographs from his voyages to Egypt, across the Alps or to Russia. To each historical photograph comes an image of what it looks like now. So people can see change. The photographs are complemented with stories from people about this places and literary descriptions of this places.
An important aspect is participation. Users should be able to upload their own hostorical photographs and they should be able to provide actual photos to historical photographs.
Sketches:


The User Interface of the application:






Web
Data
Team
- mbruellmann
- quirulum
- Ricardo Joss
- Daisy Larios
- Jia Chyi, Wang
- Sabrina Montimurro
SQL RDF MAPPER
converts SQL Data into RDF Data
Semweb provides its own developped SQL RDF Mapper to convert table data into RDF Data.
The mapper was used to build RDF data for glam_rdf_data_online and glamsearchportal.
For each table in a database, it displays table schama with information on keys and permits the definition of one or several maps using TURTLE expressions, which are evaluated inside a sesame RDF model.
A single tenant online version will be available for the duration of the hackaton under the link https://ch.semweb.ch:8151/SQLRDFSTAR/GUI.jsp
Note : This mapper is freely available until July 31 2016. From July 25 2016 on, a similar but much more secure service will be available upon https://rdflink.ch
"User manual"
The user selects one table and press the orange button to create a first blank TURTLE MAPPING SCHEMA. Once the TURTLE SCHEMA appears, the user can define a mapping for the key of the record and several mappings for each of the table columns. Inside each mapping several functions can be used:
- Explosion of a single column value by means of a separator (e.g. "one,two,three" exploded by ",")\
- Extraction of regular expressions out of values\
- If-Then expression (do map, donot map)\
- Table lookp in other table while mapping
Inside a TURTLE Mapping several maps can be defined, one for each SPARQL Endpoint. For instance if you wish to scan a table and map one RDF code to one RDF Store and another RDF code (might be different) to another RDF Store, then you define two mappings.
Testing a Mapping
Before you execute a map you should validate the TURTLE syntax and after successful validation you should store that mapping and make a version.
Then you can test a validated map on 1 or 2 records using the verbose option, click on one generated link and see what has been mapped.
another way to test a map is to define from-which records you would like to test, then to start the online tool by licking on the table symbol on the left of a table record. This online tool permits you to see the table records together with the mapped triples, as pictures 2 and 3 show.
Important: Use this mapper one at a time, since it is not (yet) multi-tenant.
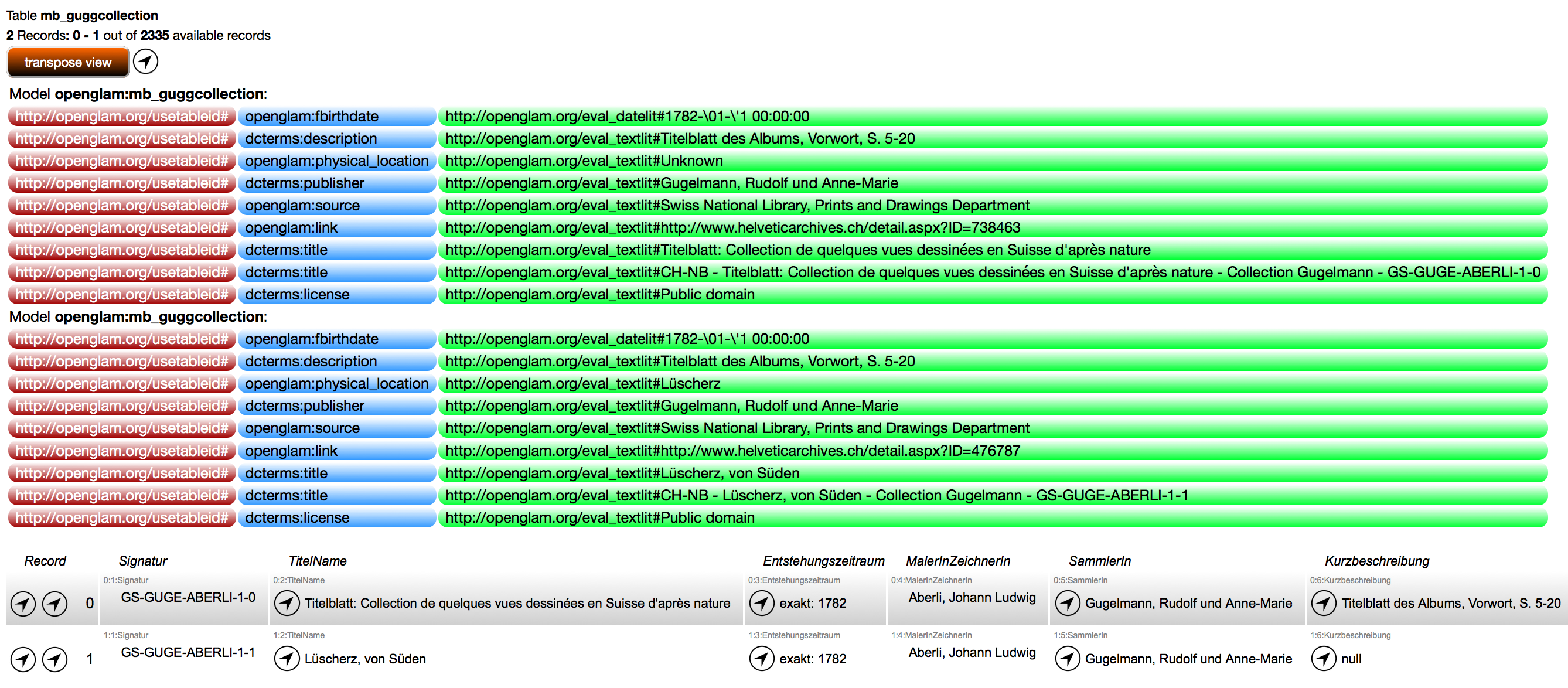 Picture 2: Online Tool showing a map of a table - triples above, records below
Picture 2: Online Tool showing a map of a table - triples above, records below
![]() Picture 3: Online Tool showing the same map of a table - triples above, transposed records below
Picture 3: Online Tool showing the same map of a table - triples above, transposed records below
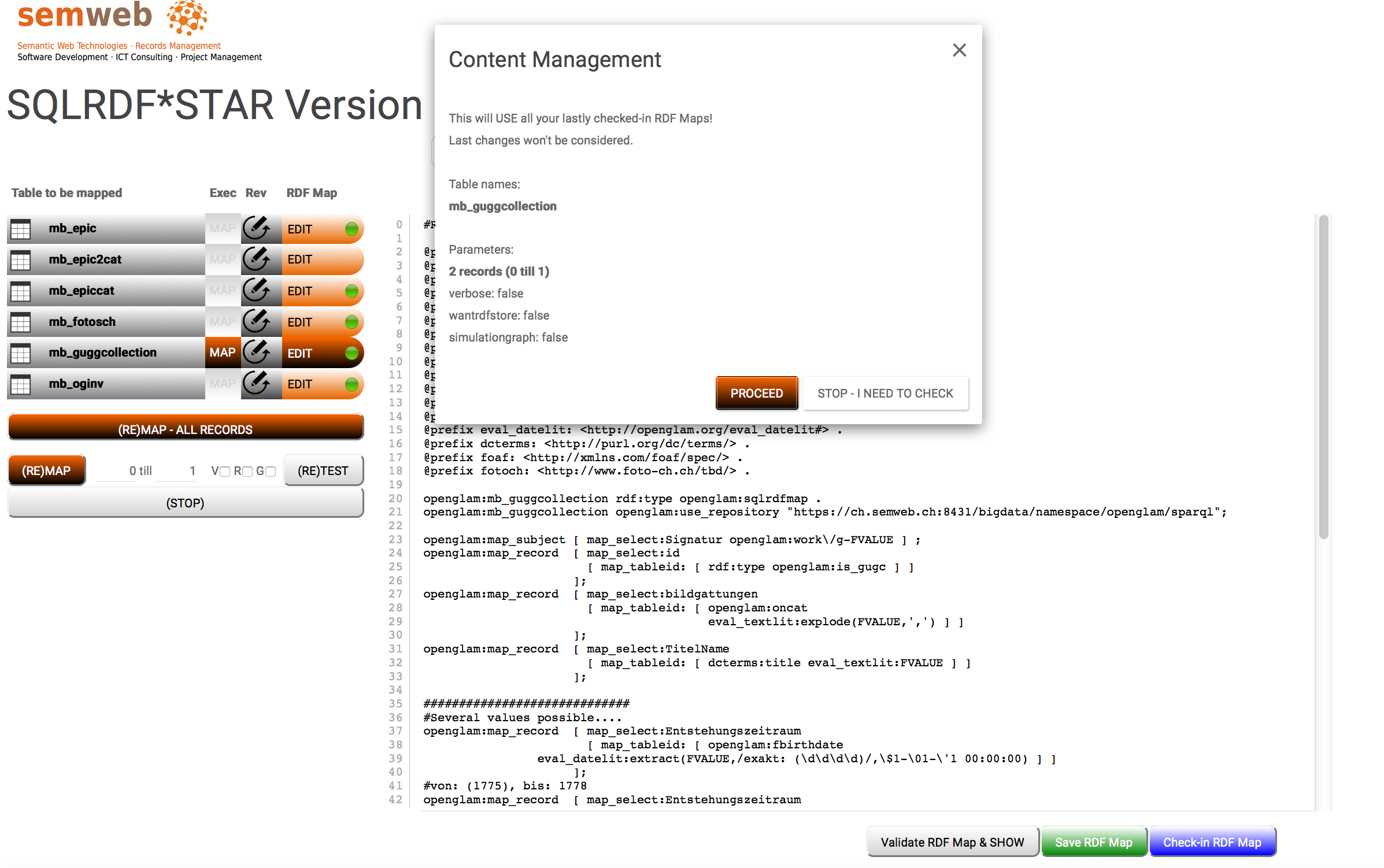 Picture 4: Execution dialog (before start)
Picture 4: Execution dialog (before start)
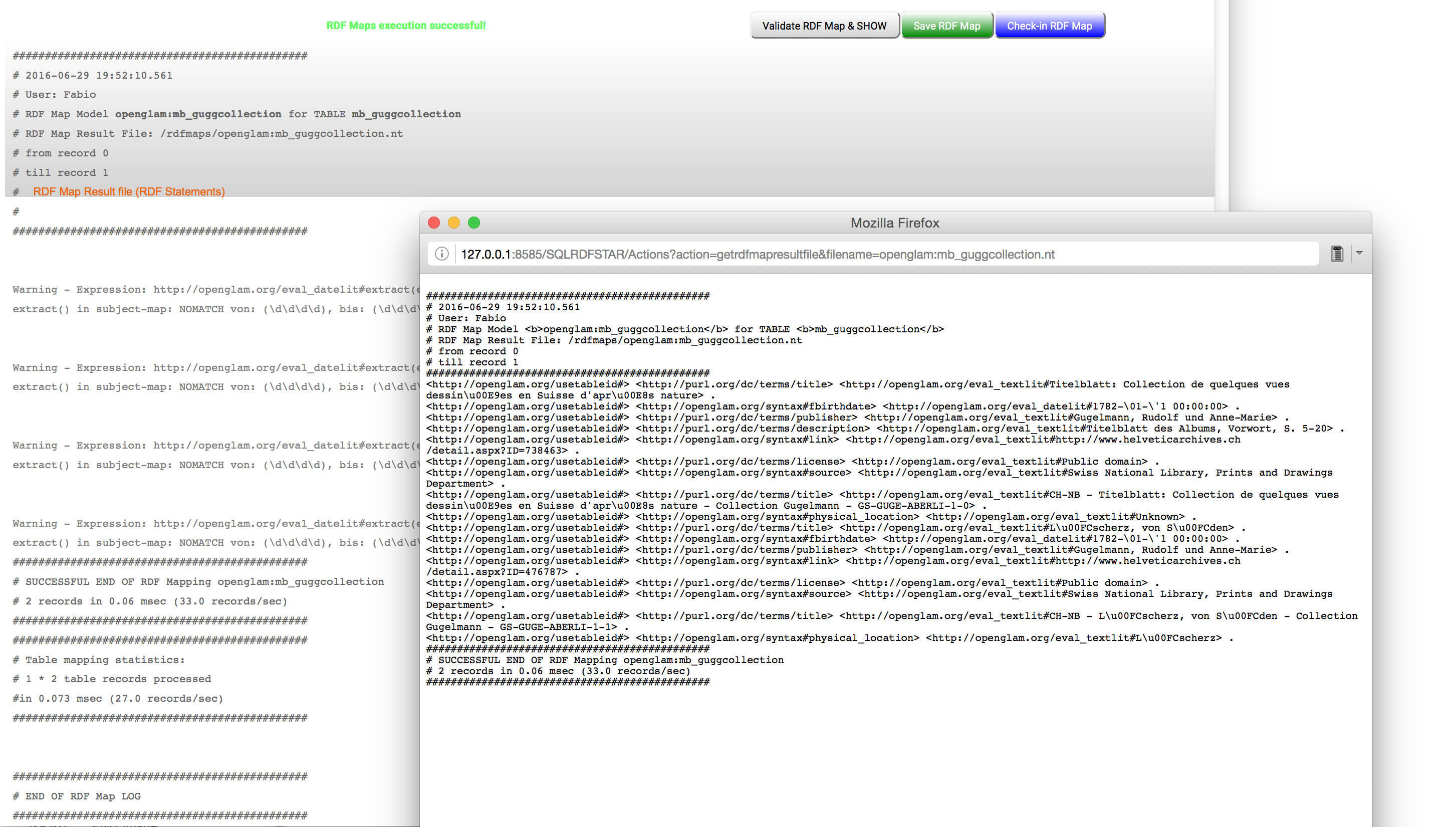 Picture 5: Execution results
Picture 5: Execution results
MAPPER FUNCTIONS
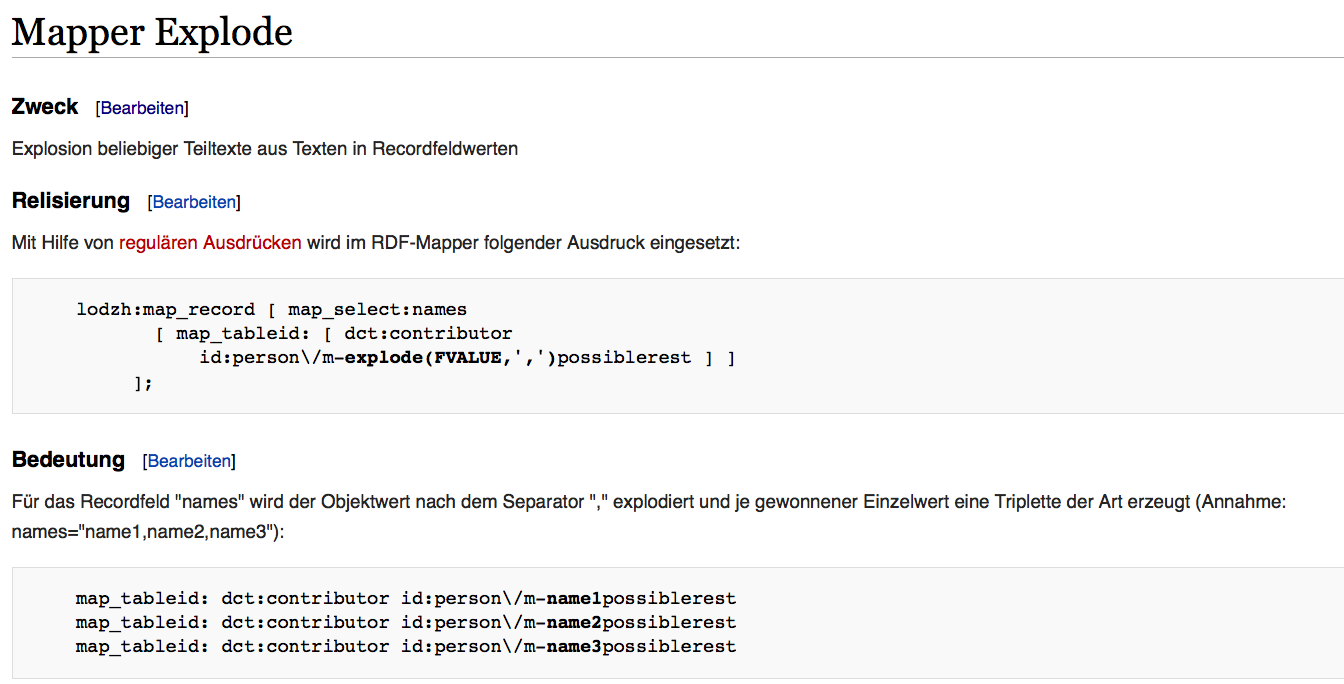 Picture 6: Mapper explode function (German)
Picture 6: Mapper explode function (German)
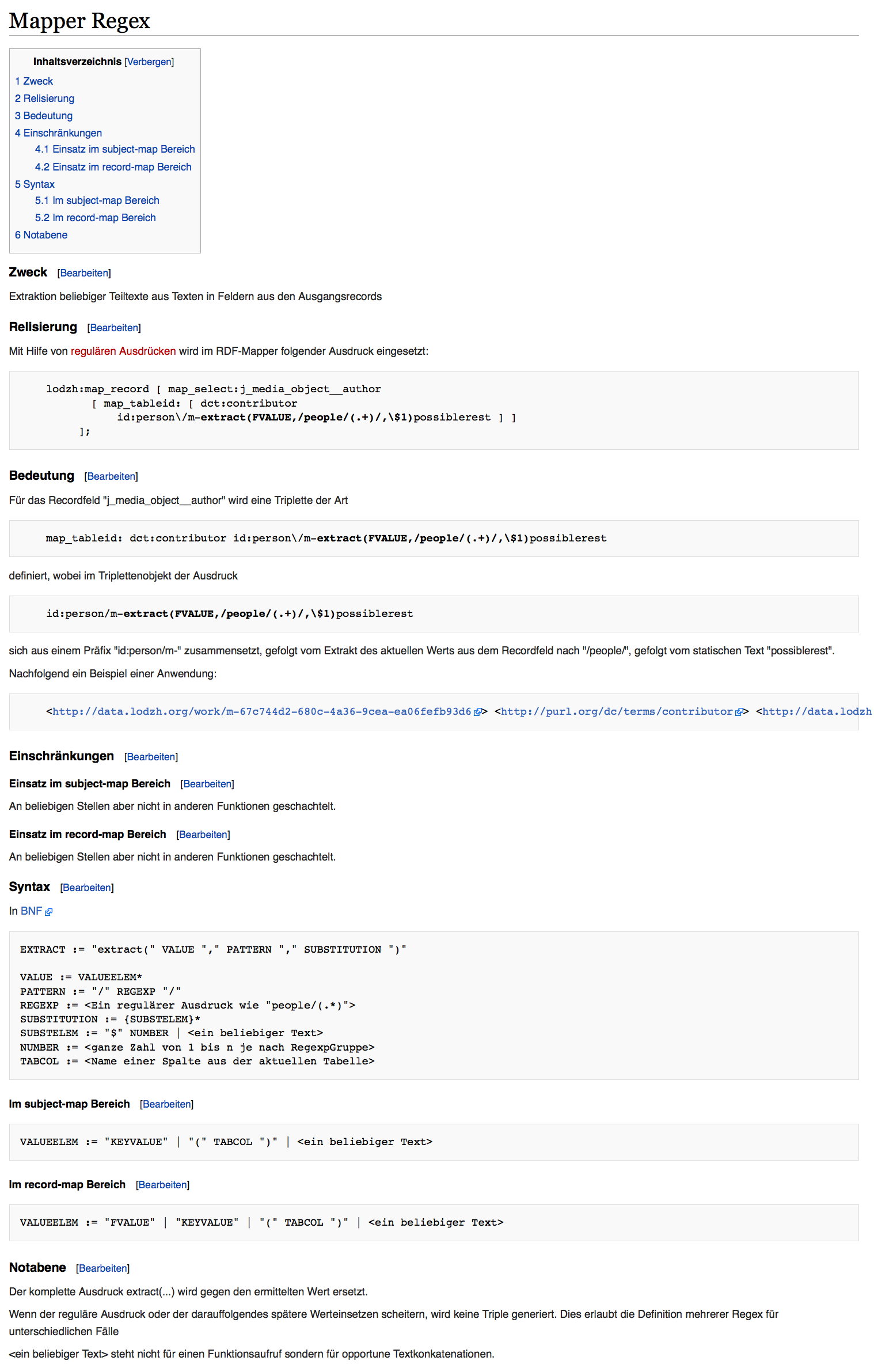 Picture 7: Mapper regex function
Picture 7: Mapper regex function
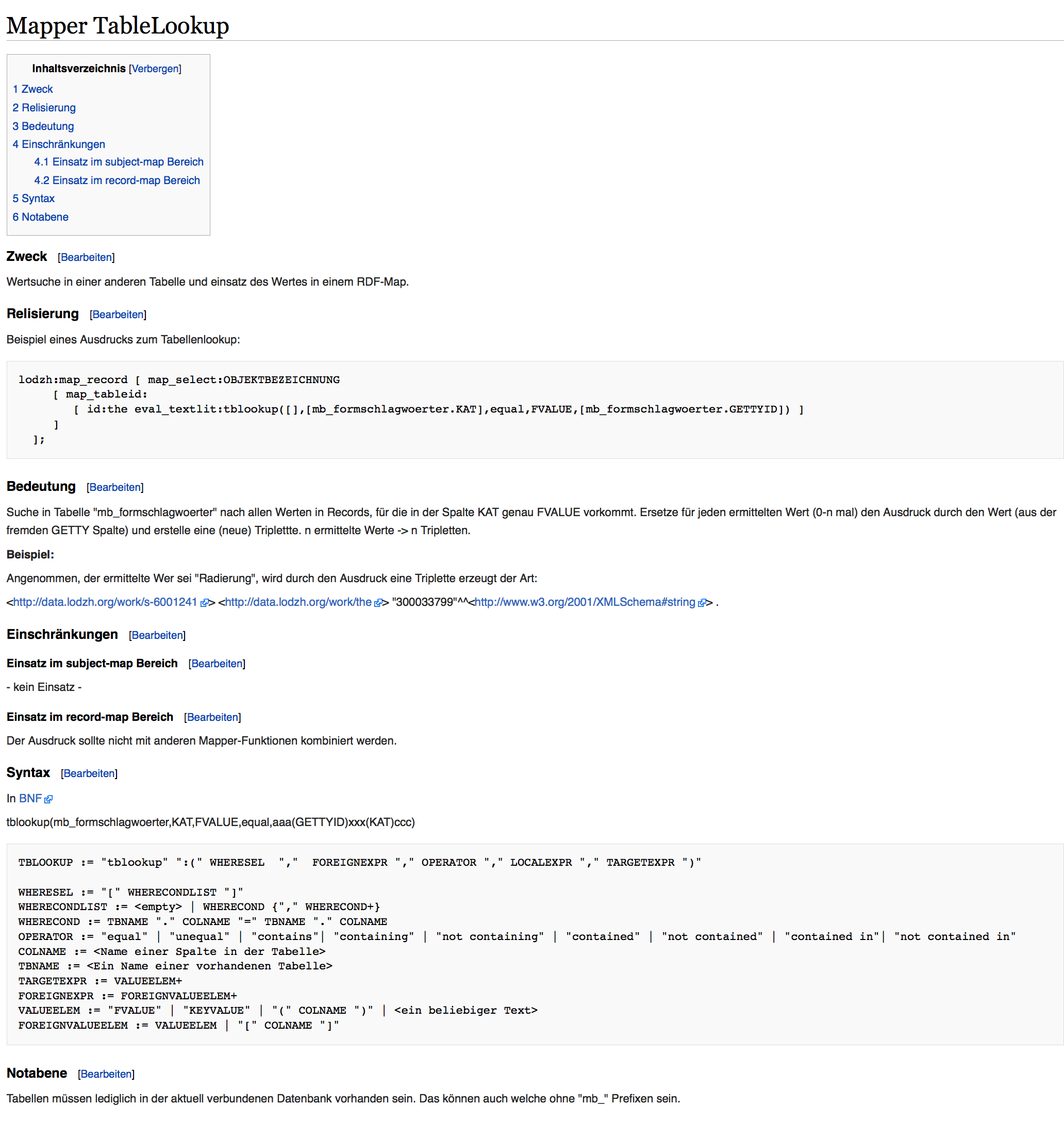 Picture 8: Mapper table lookup function
Picture 8: Mapper table lookup function
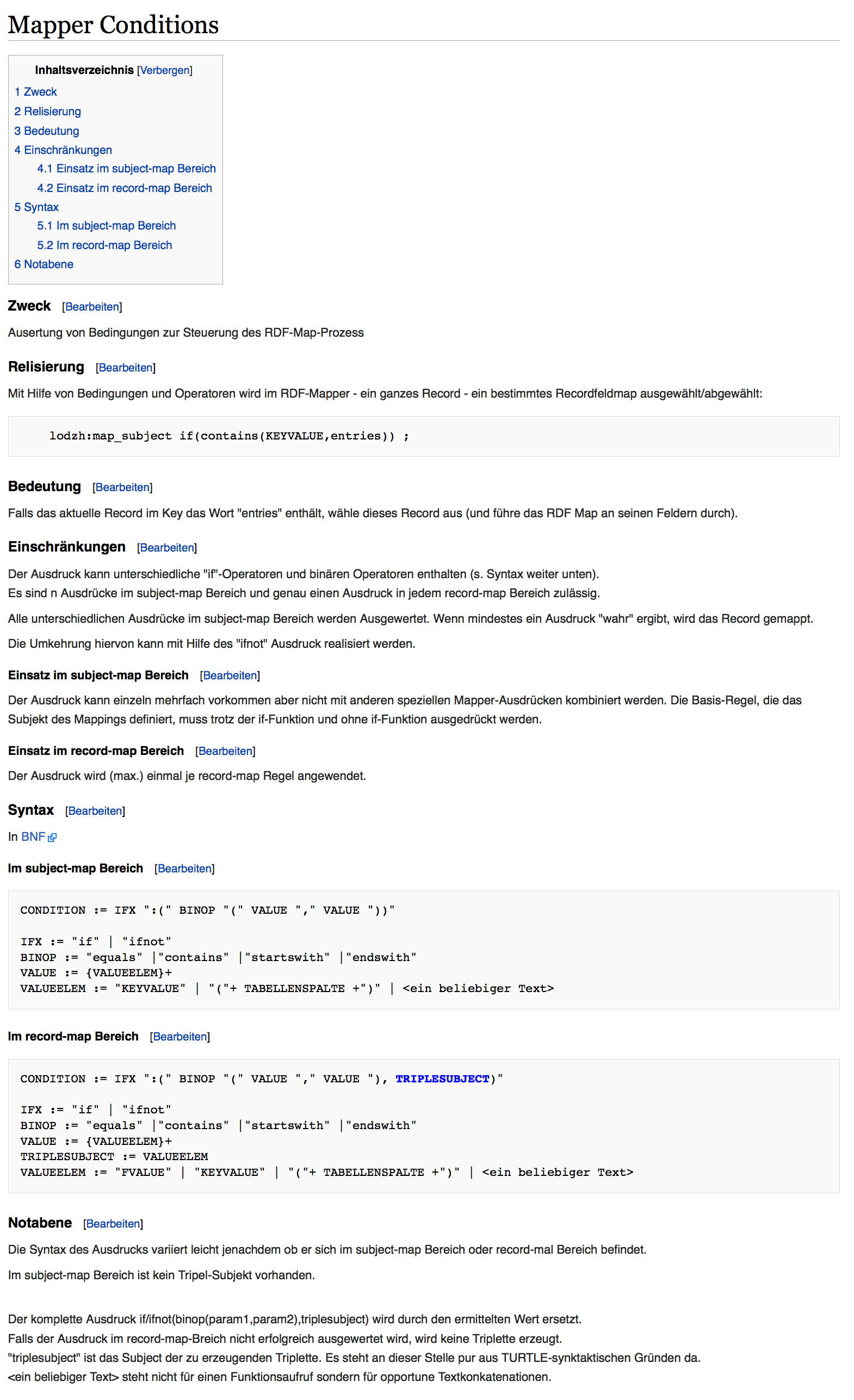 Picture 9: Mapper if-then function
Picture 9: Mapper if-then function
Data
Data for this tool are SQL tables.
Date must be uploaded into the table.
If you do not find an upload mechanism on the main page, please ask me (Fabio Ricci) to upload your table data.
Team
Swiss Libraries on a map
Map all libraries from Swissbib.
Data
Tools
- cleaning with OpenRefine
- geocoding with google maps API and qgis
- mapping with cartoDB
Result
- List of libraries from swissbib and geocoordinates (last 2 columns) : http://make.opendata.ch/wiki/_media/project:libraries_switzerland2_2.xlsx
- Map with respect to size of libraries : https://liowalter.cartodb.com/viz/85d3d60c-4069-11e6-bff3-0ecd1babdde5/public_map
- Map with library networks : https://liowalter.cartodb.com/viz/b185b31a-4069-11e6-b232-0e3ff518bd15/public_map
- The tool was completed and put to production at Swissbib in 2019: https://www.swissbib.ch/Libraries
Team
- liowalter with lot of inputs from André Ourednik, Maïwenn Bouldic, Guenter Hipler, Silvia Witzig
Visual Exploration of Vesalius' Fabrica
Screenshots of the prototype




Description
We are using cultural data of a rare copy of DE HUMANI CORPORIS FABRICA combined with a quantitive and qualitative analysis of visual content. This all is done without reading a single text page. That means that we are trying to create a content independent visual analysis method, which would enable a public to have an overview and quick insight.
Process


Clickable Prototype
https://invis.io/CA7UANERP#/171175666_20160702_02_Mockup-01
Some Gifs
Data
- http://www.e-rara.ch/bau_1/content/titleinfo/6299027
- https://en.wikipedia.org/wiki/De_humani_corporis_fabrica
Team
- yaay
- Radu Suciu
- Nicole Lachenmeier, www.yaay.ch
- Indre Grumbinaite, www.yaay.ch
- Danilo Wanner, www.yaay.ch
- Darjan Hil, www.yaay.ch
- Vlad Atanasiu
Visualize Relationships in Authority Datasets
Visualize Relationships in MACS with Neo4j
Raw MACS data:

Transforming data.
Visualizing MACS data with Neo4j:

Visualization showing 300 respectively 1500 relationships:

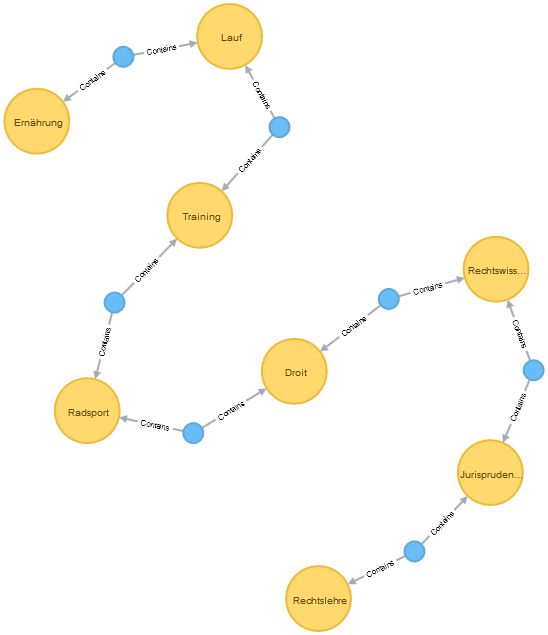
Visualization showing 3000 relationships. For an exploration of the relations you find a high-res picture here graph_3000_relations.png (10.3MB)
{kind=link}

Please show me the shortest path between "Rechtslehre" und "Ernährung":
Some figures
- original MACS dataset: 36.3MB
- 'wrangled' MACS dataset: 171MB
- 344134 nodes in the dataset
- some of our laptops have difficulties to handle visualization of more than 4000 nodes :(
Visualize Relationships in GND
content follows
Datasets
- MACS - Multilingual Access to Subjects http://www.dnb.de/DE/Wir/Kooperation/MACS/macs_node.html
- GND - Gemeinsame Normdatei http://www.dnb.de/DE/Standardisierung/GND/gnd_node.html
Process
- get data
- transform data (e.g. with "Metafactor")
- load data in graph database (e.g. "Neo4j")
*its not as easy as it sounds
Team
- Günter Hipler
- Silvia Witzig
- Sebastian Schüpbach
- Sonja Gasser
- Jacqueline Martinelli
VSJF-Refugees Migration
Mapping the fates of Jewish refugees in the 20th century.
We developed an interactive visualization of the migration flow of (mostly jewish) refugees migrating to or through Switzerland between 1898-1975. We used the API of google maps to show the movement of about 20'000 refugees situated in 535 locations in Switzerland.
One of the major steps in the development of the visualization was to clean the data, as the migration route is given in an unstructured way. Further, we had to overcame technical challenges such as moving thousands of marks on a map all at once.
The journey of a refugee starts with the place of birth and continues with the place from where Switzerland was entered (if known). Then a series of stays within Switzerland is given. On average a refugee visited 1 to 2 camps or homes. Finally, the refugee leaves Switzerland from a designated place to a destination abroad. Due to missing information some of the dates had to be estimated, especially for the date of leave where only 60% have a date entry.
The movements of all refugees can be traced over time in the period of 1898-1975 (based on the entry date). The residences in Switzerland are of different types and range from poor conditions as in prison camps to good conditions as in recovery camps. We introduced a color code to display different groups of camps and homes: imprisoned (red), interned (orange), labour (brown), medical (green), minors (blue), general (grey), unknown (white). As additional information, to give the dots on the map a face, we researched famous people who stayed in Switzerland in the same time period. Further, historical information were included to connect the movements of refugees to historical events.
Data
Code
Team
- Bourdic Maïwenn
- Knowler Rae
- Noyer Frédéric
- Stark David
- Tutav Yasemin
- Züger Marlies
Mapping the fates of Jewish refugees in the 20th century
Technical details
Setup
To work properly, the project must be hosted on a web server. The easiest way of doing this is to run server.py, which will then serve the project at http://localhost:8000/.
Source Data
The main data is stored in data.tsv, as a record of places and times. In addition, colorcodes.json defines the colors used for different kinds of places, eg hospitals are green and KZs black. important_events.tsv lists historically relevant events. famous_people.json lists the fates of some individual people.
Derived Data
Locations are geocoded using Google APIs, and cached in geocodes.tsv to prevent hitting rate limits. To re-code data.tsv, invoke python geocode.py code data.tsv. To see which geocodes are missing, invoke python geocode.py list data.tsv. In practice, some locations need to be geocoded by hand due to spelling errors or changes in place names.
The primary data, geocoded locations and color codes are then processed by clusters.py into clusters.json, a large data file that drives the display of information.