Report
💡 Active projects and challenges as of 07.07.2026 15:10.
Hide text CSV Data Package Print
@Lesesaal
Antikythera Mechanism
The Antikythera mechanism was a dedicated astronomical calculator in Ancient Greece. The 2200 year old device is the first known analog computer in history.
In 1900, a crew of sponge divers discovered the wreck of a Roman-Greco vessel that had sunk off the coast of the Greek island Antikythera around 60 BC. Numerous artifacts, such as bronze and marble statues, amphorae, pottery, glassware, jewelry and coins, were retrieved in 1901. One of the objects was an unspectacular lump of corroded bronze that proved to be the remains of the world's first known analog computer built in Ancient Greece. The so-called Antikythera Mechanism was a hand-powered model of the solar system used to calculate astronomical cycles and to predict eclipses.

Dials
82 individual parts of the Antikythera mechanism have survived, seven large fragments, known as fragments A to G, and 75 smaller fragments, which were simply numbered from 1 to 75. All parts of the mechanism were cut out of a 1 to 2 mm thick bronze sheet. The entire mechanism was originally packed in a wooden frame or box. The extensive and still ongoing reconstruction of the mechanism revealed that it served as a model for the movements of the Sun, the Moon and the planets as observable from the earth.
The front of the mechanism contains one large dial. Above and below the dial it contained a so-called parapegma – a list with the dates of heliacal risings and settings of important stars and constellations. The base of the front dial is a solar calendar. Two ring-shaped scales are part of the dial, an inner zodiac scale and an outer date scale. The inner ring scale was divided into 12 sections for the 12 signs of the zodiac. The outer ring scale was divided into 365 sections for the 365 days of the year according to the Egyptian calendar: 12 months of 30 days each and 5 additional days. The movement of the Sun, the Moon and the 5 planets known at the time – Mercury, Venus, Mars, Jupiter and Saturn – were visualised on the front. The current position of the celestial bodies in the zodiac at a certain point in time could be read off on the front dial. Additionally, the front contained a sphere, which illustrated the current phase of the moon.

The back of the mechanism contains two large and three small dials. The basic unit of the two large back dials is the synodic lunar month. The upper large spiral-shaped dial is a lunar calendar which was scaled with the 13 month names of a lunisolar calendar used at the time. When the sun pointer on the front was turned 19 times (19 solar years), 235 synodic months were traversed on the back. This astronomical connection between 19 solar years which equal 235 synodic months with good precision is known as the Metonic cycle. The large upper dial encompasses two smaller dials. The existence of the one on the left side is backed by the discovery of the number 76 in the inscriptions. This led to the assumption that this refers to the 76-solar-year Callippic cycle. The Callippic cycle consists of four Metonic cycles, after which one day had to be skipped in order to realign the solar and lunar time-keeping. The upper right dial is the so-called games dial. It contains the names of several important pan-hellenic feasts such as the Olympiads and of some smaller local ones within a four-year cycle.
The lower large spiral-shaped dial on the back is an eclipse calendar which was scaled with 223 synodic lunar months, the so-called Saros period. After 223 synodic lunar months eclipses repeat under similar circumstances. The synodic months in which a solar eclipse and/or a lunar eclipse took place were marked with glyphs. In the current reconstruction the large lower dial encompasses one smaller dial. It is tightly connected with the eclipse calendar – it extends the eclipse calendar to three times the value of the Saros period. One Saros period has a surplus of about eight hours. After three Saros periods – one Triple-Saros or Exeligmos – this surplus adds up to 24 hours and thus one full day. The small Exeligmos dial was divided into three sectors, which indicated whether the time of day indicated on the main scale applied, or whether 1/3 or 2/3 days were to be added.
Project
The Antikythera Mechanism project @ https://www.thomasweibel.ch/antikythera/ was a challenge entry for the 10th Swiss Open Cultural Data Hackathon taking place on Sept 6/7 in Lucerne. It aims at providing an accurate and freely accessible VR model for education and study porposes. The project visualizes the mechanism according to the actual findings in the existing fragments, despite plausible speculations proposing additional gearwork also visualizing the movements of the five planets (Mercury, Venus, Mars, Jupiter and Saturn) known at the time.
The VR model can be downloaded here (GLB format, 42MB) and viewed here.
Sources
- Almagest, International Journal for the History of Scientific Ideas 2016.1: The Inscriptions of the Antikythera Mechanism (https://www.brepolsonline.net/toc/almagest/2016/7/1)
- Aristeidis, V., Christophoros, M., & Andreas, V. (2023). Reconstructing the Antikythera Mechanism lost eclipse events applying the Draconic gearing the impact of gear error. Cultural Heritage and Modern Technologies, (1), 1-68.
- Efstathiou, K., Efstathiou, M., & Basiakoulis, A. (2023). The artistic complexity of the Antikythera Mechanism: a comprehensive tutorial. Proceedings of the European Academy of Sciences and Arts, 2.
- Freeth, T. (2012). Building the cosmos in the Antikythera mechanism. From Antikythera to the Square Kilometre Array: Lessons from the Ancients, 18.
- Freeth, T., Bitsakis, Y., Moussas, X., Seiradakis, J. H., Tselikas, A., Magkou, E., ... & Edmunds, M. G. (2006). Decoding the Antikythera mechanism: investigation of an ancient astronomical calculator. Nature, 444(7119), 587-591.
- Freeth, T., Higgon, D., Dacanalis, A., MacDonald, L., Georgakopoulou, M., & Wojcik, A. (2021). A Model of the Cosmos in the ancient Greek Antikythera Mechanism. Scientific reports, 11(1), 5821.
- Freeth, T., Jones, A., Steele, J. M., & Bitsakis, Y. (2008). Calendars with Olympiad display and eclipse prediction on the Antikythera Mechanism. Nature, 454(7204), 614-617.
- Freeth, T., & Jones, A. (2012). The cosmos in the Antikythera mechanism. ISAW Papers.
- Freeth, T. (2014). Eclipse Prediction on the Ancient Greek Astronomical Calculating Machine known as the Antikythera Mechanism, PLoS One 9.7, 1-15. (https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0103275)
- Freeth, T. (2022). An Ancient Greek Astronomical CalculationMachine Reveals New Secrets, Scientific American 326.1, 24-33. https://doi.org/10.1038/scientificamerican0122-24
- Gautschy, R., & Battistoni, F. (2020). Der Antikythera-Mechanismus, in: R. Färber & R. Gautschy (Hrsg.), Zeit in den Kulturen des Altertums. Antike Chronologie im Spiegel der Quellen, 419-434.
- Iversen, P. A. (2017). The calendar on the Antikythera mechanism and the Corinthian family of calendars. Hesperia: The Journal of the American School of Classical Studies at Athens, 86(1), 129-203.
- Iversen, P., & Jones, A. (2019). The Back Plate Inscription and eclipse scheme of the Antikythera Mechanism revisited. Archive for History of Exact Sciences, 73, 469-511.
- Jones, A. (2017). A portable cosmos: revealing the Antikythera mechanism, scientific wonder of the ancient world. Oxford University Press.
- Jones, A. (2019). Antikythera Mechanism Fragment A 3D model. New York University. Faculty Digital Archive. https://archive.nyu.edu/handle/2451/60402
- Oechslin, L. (2014). Antikythera. Ochs und Junior. https://www.ochsundjunior.swiss/de/antikythera/
- Voulgaris, A., Mouratidis, C., & Vossinakis, A. (2018). Conclusions from the functional reconstruction of the Antikythera Mechanism. Journal for the History of Astronomy, 49(2), 216-238.
- Voulgaris, A., Mouratidis, C., & Vossinakis, A. (2022). Assembling The Fragment D On The Antikythera Mechanism: Its Role and Operation in The Draconic Gearing. Mediterranean Archaeology and Archaeometry, 22(3), 103-103.
Team
Prof. Dr. Rita Gautschy, University of Basel/DaSCH
Prof. Thomas Weibel, University of Applied Sciences of the Grisons/Berne University of the Arts
@Lesesaal
Cyanometer
A Cyanometer is a scientific instrument from the 17th century made for measuring the blueness of the sky. This project provides a digital cyanometer for smartphones.
A cyanometer is a simple ring made of cardboard or wood. Its segments show 52 shades of blue, from light to dark. If you hold the cyanometer against the sky, you will always find a value that matches the current sky color.

The cyanometer was invented by the Geneva naturalist Horace Bénédict de Saussure in the 1760s. De Saussure realized that the blue value reflects the amount of water (or pollution) in the air: The bluer the sky, the less vapor or particles, the whiter, the more. De Saussure applied the shades of blue with watercolor to a total of 52 strips of paper, which he glued to a wooden or cardboard ring, from white, which de Saussure labeled "0", through all shades of blue to black which had the value "52". The deepest blue de Saussure measured himself was 39 degrees on the summit of Mont Blanc in 1787.
The instrument itself seems simple, but its sophistication lies in the calibration leading to a set of equidistant color shades. De Saussure used to give away self-made cyanometers to scientist friends whom he encouraged to measure the blue of the sky in as many different places of the world as possible. In fact, young Alexander von Humboldt carried such a cyanometer with him in 1802 when he climbed the 6263-metre-high Chimborazo in Ecuador, which was considered the highest mountain on earth at the time. When von Humboldt reached the summit the weather cleared, revealing the darkest blue ever measured up to that point: 46 degrees on the cyanometer.
The Cyanometer project @ https://www.thomasweibel.ch/cyanometer/ provides a freely available copy of the instrument.
Usage
Launch Cyanometer on your smartphone and grant access to the camera. Turn away from the sun, point the center to the sky and adjust the color using the red slider. The number indicates the current shade of blue. A normal, clear midday sky at sea level will be around 23 degrees.
Sources
- Barry, R. G. (1978). H.-B. de Saussure: the first mountain meteorologist. Bulletin of the American Meteorological Society, 59(6), 702-705.
- Breidbach, O., & Karliczek, A. (2011). Himmelblau — das Cyanometer des" Horace-Bénédict de Saussure" (1740–1799). Sudhoffs Archiv, 3-29.
- Brunner, Katrin (2022, August 30): The Blue of the Sky. Swiss National Museum (https://blog.nationalmuseum.ch/en/2022/08/blue-sky-de-saussure/)
- Hoeppe, G. (2007). Why the sky is blue: discovering the color of life. Princeton University Press.
- Karliczek, A. (2018). Zur Herausbildung von Farbstandards in den frühen Wissenschaften des 18. Jahrhunderts. Ferrum—Farben der Technik—Technik der Farben/Colors in Technolog—Technology of Colors, 90, 44-45.
- Winkler, J. (2017). Material blue. Contemporary Aesthetics (Journal Archive), 15(1), 26.
- Werner, P. (2006). Himmelsblau: Bemerkungen zum Thema „Farben “in Humboldts Alterswerk Kosmos; Entwurf einer physischen Weltbeschreibung, 85-86.
Team
Prof. Thomas Weibel, University of Applied Sciences of the Grisons/Berne University of the Arts.
@Lesesaal
Antoin Sevruguin: Iranian Photography
Based on Iran photography from the collections of the Ethnographic Museum UZH and the Museum Rietberg in Zurich, we will discover the use of Wikimedia Commons in an GLAM context. The challenge is mostly aimed at people from GLAM institutions without an IT background who are interested in how to make their collections accessible through the wikiverse.
Documentation: Images on Wikimedia Commons, using Wikidata and OpenRefine
Thanks
This text was compiled by Joris Burla based on various documents and insights from the various members of the challenge. My thanks go out to you all, without whom these two days would not have been so insightfull. I thank especially to Daniela Zurbrügg, who was open to bring the historical photographs from the Ethnographical Museum of the UZH and publish the museums first open data. The members of the challenge over the two days were:
- Daniela Zurbrügg
- Axel Langer
- Amelia Lipko
- Jonas Lendenmann
- Diego Hättenschwiler
- Martin Thurnherr
- David Beranek
- Francesca Altorfer
- Philipp von Essen
- Dominik Sievi
If you want to save this documentation, you can download a PDF version here: https://s3.dribdat.cc/glam/c/11544/AVWE4GAPIOIVJOT51G84LNBO/Documentation_GLAMhack_2024.pdf
Beware that this is mainly a documentation of our process and not a general how-to. I believe though that many parts can easily adapted and generalized. If you see errors, have additions or other feedback, please send me a mail!
Antoin Sevruguin
Antoin Sevruguin was an iranian-armenian photographer mainly active in the late 19. c. in Qajar Iran. The Museum Rietberg (MRZ) as well as the Ethnographic Museum at the UZH (VMZ) both have a number of albums with photos mainly ascribed to Sevruguin in their collections. In total there are around 500 photos in these albums. Since most of the original negatives of Sevruguins burned down in the beginning of the 20. c. it is difficult to reconstruct which photos are actually by Sevruguin and which by other Iranian photographers (for example Abdullah Qajar (1849–1908/1912) or laymen photographers (for example Ernst Hoelzler (1835–1911). Adding those photos to wikimedia commons could greatly increase the availability for researchers and would expand the already existing images by Sevruguin on wikimedia commons – uploaded by other institutions from around the world. This challenge for the GLAMhack 24 was about learning about the best practice for GLAMs to upload photos from their collection to Wikimedia Commons, learn about Wikidata, learn about the use of OpenRefine, do a first batch upload, and get in a discussion about the best ways of describing the photos, taking into account the historic descriptions in the albums. The members of our group had various backgrounds: Being active in the wikivers for decades, being curators for westasia and photos, coming from documentation or digital humanities.
Learning about Wikimedia Commons and the Wikiverse
A first step was learn about Wikimedia Commons and the Wikiverse in general. Thanks to our longtime wikimedians Diego and Martin, everyone started to understand the distinction between the different sister projects Wikidata, Wikimedia Commons, and Wikipedia and how they are connected and enriching each other. Of course Wikimedia Commons was the focus: We learned how to upload a single (or up to 25) images directly with the Upload Wizard. This way of uploading is what is mainly used wikimedians like Diego and Martin, which also makes sense: Their usecase is to upload only a few images at a time, adding the metadata about the image and the depicted topics manually at the same time as uploading it. This way one has control over the single image, and can really enrich the wikitext and structured data of the few images being uploaded. It is also possible to copy the information of the first image uploaded and use it for the next batch of photos that have the same metadata. From the view of GLAMs this way is maybe to slow and might double the work: usually an institution has a big batch of images (more than 25 at a time) and has already at least some metadata documented in their documentation software which in turn can be exported as an excel. It is here where the process with OpenRefine has the big impact – for only uploading a few images without already existing metadata it might be too much work.
Content consideration
Before we actually uploaded images to wikimedia commons, there was also a lively discussion about the content, content warnings as well as titles. These thoughts were specific about the images form Sevruguin, but can be expanded to other images of course as well.
Titles
Since the images of by Sevruguin don't have original titles given by Sevruguin, it was very difficult to come up with a good solutions for the titles. The photographs did have some titles given by the collectors from around 1900, and while these serve as a historical source, the museums don't want to reproduce racial stereotypes and wrong attributions, or at least mark it as a historical naming. This of course is a bigger discussion that is also discussed in different working groups from different swiss institutions. Here the ETH published guidelines on how they work on problematic titles or descriptions of objects in their collections. In the case of the photographs in the collection of the VMZ, we decided to use the title from the album, but also clearly mark it as being a historical attribution: Example: The legend in the album for VMZ.523.01.037 was "Armen. [Armenische] Nonnen in Djoulfa". For the wikidata item we only used the inventory number as the label, and added a description with the given legend: "Fotografie von Antoin Sevruguin, Bildunterschrift auf Albumseite: "Armen. [Armenische] Nonnen in Djoulfa", aus der Sammlung des VMZ". In this way, it is clearly marked as being historical. The downside is that the description of the wikidat item is not shown on wikimedia commons, and only the inventory number is given as a title. To counter that we decided to write the same line as a description on wikimedia commons. The filename on wikimedia commons was another point of discussion. Since it is very difficult to change afterwards, it needs to be as correct as possible from the start. While in the guidelines on uploading files with OpenRefine state that it might be helpful to name the files with a more descriptive name, we concluded that it could actually create more problems down the road (as well having the same issues as above). We decided to name it with the inventory number and the name of the creator. But also this turned out to be not a good decision: While working on it, we got the information that one of the photos already uploaded beforehand by the MRZ was wrongly attributed to Sevruguin and is actually shot by another photographer. While the metadata is easy to change, the title will still say "Sevruguin".
Sensitive Content
Images can also contain sensitive content, i.e. showing violence or sick and dead people. While there are guidelines on nudity on wikimedia commons, there are no guidelines on images depicting violence. After some discussion we decided to not upload one image of hanged people, even though it can be found on various websites. We don't know if this is the way to go forward, since it hinders a complete overview. Putting an editorial blur the image could be an option and has been done on various museum collection websites, but we don't know if this could also be solution for wikimedia commons.
OpenRefine Process
Daniela from the VMZ brought with her as a testing file an excel export from the museums database. This excel was a simple export of certain fields without any processing of the data at the time of the export. This is probably the most common case. If it is possible to already prepare the export better, the whole process can get even smoother. The following description is not a full tutorial on OpenRefine, but focusses on the process for GLAMs. There are already some good tutorials online, either on youtube to follow along, or on the wikiversity. Here is the header of the file, with a sample line (splited in two, due to formatting):
| Beschreibung | Anmerkung zur Beschreibung | ist Teil von | Datierung | Zusatz Datierung | Fotograf:in | Material/Technik |
|---|---|---|---|---|---|---|
| "Persischer Dorfbewohner" | handschriftliche Notiz auf Albumseite | Album Iran 1 (VMZ 523.01) | 1880-1900 | ca. | Sevruguin, Antoin | Albuminpapierabzug |
| Masse Foto in cm_HxB | Land | Ort | Bemerkungen geografische Zuordnung | Bemerkungen zum Objekt | Beschriftungen im/auf Bild |
|---|---|---|---|---|---|
| 20 x 13 | Iran | früher: Persien | 97 |
This already gives almost all of the necessary information for an upload on wikidata, but a few columns needed to be changed or added. For the purpose of learning to use OpenRefine it was perfect!
- Spliting columns: The column "Datierung" as well as "Masse Foto in cm_HxB" needed to be split into two separate columns. This can be done by going to Edit column -> Split into several columns... and then specify the seperator. In this case it was "-" for the dating and " x " for the dimensions (take note of the extra spaces being part of the seperator!)
- We could also edit the column which had the content "früher: Persien": We learned, that it was actually called "Qajar Iran" at the time of Sevruguin. By editing one cell and then clicking on "Apply to all identical cells", this was easily done for the whole file.
- We also changed the column "Beschreibung" to the above mentioned longer description. We used Edit cells -> Transform and then added the extra content before and after the existing values: "Fotografie von Antoin Sevruguin, Bildunterschrift auf Albumseite: "+value+", aus der Sammlung des VMZ".
- Since the image files were named with the inventory number, but had underscores instead of dots, we already needed to peak a little into GREL, but just a little. We added a new column on the base of the inventory number: Edit Column -> Add Column based on this column. We then replaced the dots by underscores: value.replace('.','_')
These are the most basic editing tools, and a combination of them will get you very far already! GREL can get you very far, but it also gets very complicated quickly.
Reconciling
Reconciling is a way turning your text into links to wikidata. It is also needed to create new entries in wikidata as well as wikimedia commons. Most of the statements of a wikidata item are linking to an other wikidata item, while measurements or dates are not necessary to link, of course.
- Reconcile all the columns you want to use for the wikidata item, like "Material/Technik", "Fotograf:in" or "Land", by going to Reconcile -> Start reconciling. It will then ask you to chose which wikibase you want to use, we chose wikidata to create the links to the wikidata items. Sometimes it already recognises a type and suggest to only search for items with that type (for example "human" for the column "Fotograf:in"), otherwise it just searches all of wikidata. Start reconciling!
- Matching the links: sometimes (for example for Sevruguin) it found directly the correct wikidata item - the entry in the cell turns blue and by hovering over it you can see a preview of the wikidata item linked. Othertimes, for example with "Iran", it finds multiple items which are a close match: you have to choose the correct one. By clicking on the two check marks, you choose it for all the identical cells. There will be a dark green line indicating how many percent of that colunn has been reconciled. If none of the given option is the correct one, you can also search for the correct one.
- To create new items for each artwork or collection item, you need to have one columns marked for that. The easiest way is to use the column for the label, in this case the "Inventarnummer". If you reconcile this column, it wont find any wikidata item to match (hopefully!). it will give you the option to create a new item based on that cell. If you go to Reconcile -> Actions -> Create a new item for each cell you can do that for the whole column. There will be a bright green line indicating that this is the one to create new items.
Be sure to reconcile all of the data that you need, before you go on to the next stage. If you already building you schema and then change the strucure of the data, OpenRefine has a hard time to update the schema to the new structure. Usually, you have to delete the schema and start anew.
Building the schema
By going to Extension: Wikibase -> Edit Wikibase Schema the view changes, now it is time to "build" the wikidata item. These schemas can be saved – which is speeding up the process tremendously for any further uploads. if you always have the same export with the same labels, you only need to build the schema once.
By clicking on "Add item" you tell OpenRefine to create a new item. You can then add the column headings to the correct spot: to actually add a new item, the reconciled column where we chose "create new item" needs to be added in the top spot. After that you can add terms and add statements. Every wikidata item needs to have a label and a description. You will need to reuse the label-column here:

By adding statements you can build your wikidata item. There a only a few rules or guidelines on what statements are need. Here is a list of statements that make sense for photos in a collection of a GLAM institute:
- instance of: should be "photograph" (Q125191), carefull to not choose "photography" (Q11633)!
- inception: the dating model on wikidata is a bit confusing. Use the overarching century/millenium and add the qualifiers "earliest date" and "latest date"
- creator
- made from material
- height
- width
- collection
- inventory number: since the inventory number isn't a general fact about the object, it needs the qualifier "collection"
- location of creation:
If you are not sure if you do it correctly, you can switch to the preview, where it shows you how it will look like. By the way: Don't get too confused by many issue that OpenRefine throws at you! There are three kind of issues, and they vary greatly in the severity:
- Information: This usually just informs you about something, for example, that you indeed will create items!
- Warnings: Wikidata loves sources for each statement. In many case, this is not neccessary, or can be added at a later date. You can generally ignore these warnings.
- Errors: Sometimes there is indeed an error – you might have forgotten to add a label to a wikidata object. These errors need to be corrected before uploading.
Upload to Wikidata
Now comes to fun and magic part, uploading the data to wikidata. Go to Extensions: Wikibase ->Upload edits to Wikibase. You will need to login again with your credentials. It again shows you all of the issues. Unless there is an Error showing, you can proceed. Give a short summary of you edit, a few words are enough. By clicking on Upload edits OpenRefine goes on to create wikidata items!
Wikimedia Commons
Now we need to switch our minds to wikimedia commons. Many of the processes are the same though!
Filepath
OpenRefine needs to know where your images are, to be able to upload them. If you use OpenRefine on PAWS, you have to upload them to the PAWS Server first, follow these steps: Running OpenRefine online. If you are running OpenRefine locally, you will need absolute file paths. In both cases, you want to create a column with the filepath. We tried both versions, and both worked fine, althoug we didn't do a stresstest with thousands of hi-res files. On PAWS, you only have 3 GB of diskspace, so that might limit you eventually.
Filename
On wikimedia, the filename has to be unique for every file! For GLAMs this can easily be achieved if you put in your inventory number and you institutions name or acronym: for example "VMZ.523.01.003.jpg" in our case. We decided to also add the creator name, although as described earlier, this can lead to problems later on and we wouldn't recomend it. In cases of photoalbums, one could use the descripitive title of the album, as the Golestan Palace Library did: "Golestan Palace Album No. 208-5.jpg" We haven't yet found any good solution. The filename is also the column that we need to reconcile, but now we need to choose wikimedia commons as the wikibase. You need to get no match – otherwise there is already a file on wikimedia commons with the same file name. As before with the label, we need to choose "Add new item for each cell". Wikimedia Commons is not available out of the box as a wikibase, you need to manually add it the first time you use OpenRefine. At Extensions: Wikibase -> Manage Wikibase instances you can choose wikimedia commons and add it easily.
Wikitext
Usually all the information about an image on Commons is stored in wikitext. This has its own syntax and can get quite complex. Every file on wikimedia commons needs to have some wikitext, but if you do the upload this way with wikidata and OpenRefine, the wikitext can be minimalized. There are basically three things that need to be in there:
- == {{int:filedesc}} ==
Here you need to add the template name, in the case of historical photographs, it is {{Art photo}}. 2. == {{int:license-header}} == Here you need to state the licence, in our case with Sevruguin, who died in 1933, we can state this like this: {{PD-Art|PD-old-auto-expired|deathyear=1933}} 3. Adding categories: all images on wikimedia commons need to be in at least one category. You need to state them in wikitext, or then afterwards with different tools. We used for example the following category: [[Category:Photographs by Antoin Sevruguin]] We found it helpfull to look at uploaded files to see what kind of categories are already in use around that topic. You should also add a category called [[Category:Uploaded by {your institution}]], so that you are able to easily track your uploads. In the end it might look like this:
== {{int:filedesc}} == {{Art photo}}
== {{int:license-header}} == {{PD-Art|PD-old-auto-expired|deathyear=1933}}
[[Category:Antoin Sevruguin]]
[[Category:Qajar Iran]]
[[Category:Photographs by Antoin Sevruguin]]
[[Category:Black and white photographs by Antoin Sevruguin]]
[[Category:Photographs by Antoin Sevruguin in the collection of Völkerkundemuseum der Universität Zürich]]
[[Category:Landscape photographs by Antoin Sevruguin]]
[[Category:Architecture photographs by Antoin Sevruguin]]
Building the Schema
Now it is already time to build your schema, this time you need to choose "Wikimedia Commons" as your Target Wikibase instance. The other steps are similiar to those above. This time around though, you will add a new item with column for the filename (which includes the file extension!). As described above, we added the description as a caption. There are some statements required as well. These statements will show up in the structured data on wikimedia commons:
- digital representation of: Here you need to add the link to your wikidata item. Since you still working in the same sheet, and already have created the item, you can drag that column here (it was "Inventarnummer" in our case). This connects the wikidata item to the image on commons. In theory, an item can have mulitple representations. Think about a 3D-Object, but maybe even a photonegative, which you upload once as thruthful negative, and once as positive.
- Urheberrechtsstatus
- Lizenz
Uploading
Now it's time to upload everthing to wikimedia commons. It is the same process as above, but this time it probably will take considerably longer, since it is actually uploading images.
Connecting the File to the wikidata item
As a last step it is helpful to connect the wikidata item also with the image. This is easy, since you already have everything you need: a column with your wikidata item, and a column with your wikimedia commons file. Just switch back to wikidata as you Target wikibase instance and add a new item based on the wikidata column. Add the statement "image" (P18) and drag the filename column there. Then upload the edits to wikidata!
And now?
Congratulations, you successfully uploaded images on wikimedia commons! These are now available for everyone, and are a valuable resource for researchers around the world.
Categorizing: Cat-a-lot
Now you can start categorize the images even more. Jonas was doing a lot of categorizing during those two days and sorted the already uploaded images by institution, as well as started to sort them by topic: landscape or portrait photography. He used a very handy tool called Cat-a-lot
Embed on Wikipedia Pages
You can now start add the uploaded photos on Wikipedia pages! Enrich Wikipedia by adding those photos any article where it might be relevant. You can do that in any language. But be aware to not add too many "unneccessary" images. If an article is very short, adding 10 images makes it unbalanced.
Benefits and Statistics
While we were busy uploading, Dominic and Francesca did a lot of Spraql queries around the topic and did some statistics. We tried to figure out how many GLAMs in Switzerland actually worked like this, when it comes to historic photographs:
SELECT ?collection ?collectionLabel ?item ?itemLabel ?value ?valueLabel
WHERE {
?collection wdt:P31 wd:Q1497649.
?collection wdt:P17 wd:Q39.
?item wdt:P195 ?collection.
?item wdt:P31 ?value.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],mul,en". } # Helps get the label in your language, if not, then default for all languages, then en language
}
This gives a long list of objects in swiss collections with a wikidata item and looks at the type. As it turns out, for historical photographs only the MRZ and the VMZ have been doing it this way. This can have various reasons which would need further research: Is it even neccessary to create a wikidata item for every photograph? But oftentimes, as Diego pointed out, did the institution upload their photographs a longer time ago, when this method was not yet available at all. But it does show the benefit of doing it that way: with sparql as a powerfull query language, it makes the images on Wikimedia Commons more easily searchable, beyond the use of categories. By simply adding "?item wdt:P18 ?pic." to the query above, it shows you the images of those items (do add "LIMIT 100" add the end of the query!).
Geographic References of Swiss and European Collection items
Francesca was also interested in geographic references for the WikiData objects in swiss and european GLAM Institutions and created from queried data following maps:
-
Map of objects from swiss GLAM institutions
-
Maps of objects from european GLAM Insitutions by depicts (dt. Motiv) and by country of origin (dt. Ursprungsland)
They show an interesting discrepancy between where objects are coming from originally and what places they are depicting. It is clear that there are many european paintings which depict european place uploaded to wikidata. Further research and analysis could be done on this - especially considering that many historical photographs dont have an wikidata item to beginn with. How would this distribution change?
Standards for describing collections artworks
It would be further interesting to compare how different institutions describe their objects on wikidata. Dominik did start on a complex excel analysis, which did not end fruitful so far. This remains to be done.
Github
You can also find the same (currently, october 2024) documentation over on github. I might be updating stuff there, and in the meantime, it just sits there as well.
From before and during the challenge:
First Success:
We figured out OpenRefine, wikidata and wikimedia commons together to upload the first three images for the Ethnographic Museum of the UZH:
Photographs by Antoin Sevruguin in the Ethnografic Museum UZH

Two girls in European Persian dress, Antoin Sevruguin (1851-1933), Iran, c. 1880-1896, albumen print, 11.8 × 16.8 cm, Museum Rietberg Zurich, Emil Alpiger Collection, inv. no. 2022.428.134, gift from the heirs of Emil Alpiger. Public Domain, via Wikimedia Commons.
Antoin Sevruguin (1851–1933) was born to Armenian parents in Iran, he grew up in Tiflis (now Tbilisi), Georgia, and later worked in Tehran. His goal was to make a portrait of his native country that was as comprehensive as possible. His oeuvre included around 7,000 photographs. During his lifetime, his photographs were already being published in European books; he was awarded gold medals in Brussels and Paris and in 1900 raised to the nobility by the shah in 1900. Artists in Iran still relate to him today. Many museum all around the world have photographs by Sevruguin in their collections. In Zurich the Ethnografic Museum UZH and the Museum Rietberg each have several albums with a few hundred photographs.
In this challenge we want to discover how images from collections can be made accessible on the wikiverse: Together we will find out, what tools can be used and what the best practices are. Maybe we are even putting together a cheat sheet for GLAM institutions or write up detailed instruction? We further explore the use of the images on wikipedia.
The challenge is mostly aimed at people from GLAM institutions without an IT background who are interested in how to make their collections accessible through the wikiverse. The format of the challenge is a open process workshop and there is no need for a specific product at end.
Dataset: Photographs in the Collection of Museum Rietberg on Wikimedia Commons
Different Perspectives on the Habsburg
Originating from the territory of today’s Switzerland, the dynasty of the Habsburg has been present in many different countries, and its members have been associated with a variety of historical events that have left their traces in our collective memories. By means of this international cooperation project, we intend to tell the story of the Habsburg from the point of view of the various populations concerned. Putting the different memories side by side, we want to seize the occasion to reconnect on a different level, leaving the Habsburg family tree and the world it stands for behind us.
GLAMhack 2024, 6-7 September, Lucerne, Switzerland
Different Perspectives on the Habsburg
Project Idea
Originating from the territory of today’s Switzerland, the dynasty of the Habsburg has been present in many different countries, and its members have been associated with a variety of historical events that have left their traces in our collective memories. By means of this international cooperation project, we intend to tell the story of the Habsburg from the point of view of the various populations concerned. Putting the different memories side by side, we want to seize the occasion to reconnect on a different level, leaving the Habsburg family tree and the world it stands for behind us.
Project teams in several countries create artistic (and possibly participatory) coverage of the perceptions of the Habsburg in their respective country. The resulting creations (presentable on a screen) would then be integrated in a website and included in installations to be displayed at Habsburg memory sites in the participating countries, juxtaposing the different perspectives in a modular fashion. An additional module could be dedicated to a participatory project involving people from all participating countries, taking the history of the Habsburg as a starting point to think about how peoples and nations would live with each other in an ideal, utopian world.
The idea is to start with sub-projects in México (Chapultepec Castle), Switzerland (Sempach battle site), Austria (various sites), and Bosnia (Sarajevo site of the assassination of Archduke Ferdinand). Further countries and memory sites could be added as the project evolves.
Current State of Advancement (September 2024)
Pilot Project in Mexico
A student group at Benemérita Universidad Autónoma de Puebla (BUAP)[1] has implemented a pilot project for México. In parallel, it is planning to reach out to Chapultepec Castle (residence of Emperor Maximilian and his wife Charlotte) and another Habsburg memory site in México.
- Short animation film: Memories of Habsburg (presented on 5 Sept. 2024)
- Short animation film: Reflections on the “making of” (presented on 5 Sept. 2024)
Projects in Switzerland, Austria, Bosnia, etc.
We are looking for cooperation partners in various countries who would be interested in developing an artistic and/or participatory project in relation to a Habsburg memory site in their country and in connecting with the other partners on an international level.
Switzerland
Habsburg Memory Sites
- Habsburg Castle (built: ca. 1020)
- Muri Abbey (founded: 1027)
- Königsfelden Monastery (founded: 1308)
- Morgarten (1315) Battle Sites
- Sempach (1386) Battle Site
- Empress Elisabeth of Austria (Sissi) - Assassination (1898) Site in Geneva / Statue
See also:
- Kauf Luzerns durch Habsburg, 16. April 1291 (Staatsarchiv des Kantons Luzern)
- Hugener, Rainer (2012): Erinnerungsort im Wandel. Das Sempacher Schlachtgedenken im Mittelalter und in der Frühen Neuzeit. In: Der Geschichtsfreund. Zeitschrift des Historischen Vereins Zentralschweiz, Jg. 165 (2012), S. 135–171.
- Elsasser, Kilian, T. (2015): Die Geschichte der Alten Eidgenossenschaft in neuen Schläuchen – eine Ausstellungskritik. In: Nike-Bulletin, 2015(3), S. 8-10.
- Neue Sicht(en) auf Morgarten 1315?, Der Geschichtsfreund. Zeitschrift des Historischen Vereins Zentralschweiz, Jg. 168 (2015).
- Niederstätter, Alois (2015): Das Morgarten-Geschehen aus österreichischer Sicht : Erinnerung und Historiographie. In: Der Geschichtsfreund. Zeitschrift des Historischen Vereins Zentralschweiz, Jg. 168 (2015), S. 45-56.
- “Die Eidgenossen kommen! Geschichten zum Aargauer Schicksalsjahr 1415 erleben (Kanton Aargau, 2024)
- Zeitgeist um 1900: Ein Rundgang durch Luzern (Kurt Messmer, Blog Schweizerisches Nationalmuseum, 2024)
International Project
The international project needs to be further specified. Several funding avenues have been identified that need to be evaluated.
Contact Persons
If you would like to cooperate and implement the project in your own country, please get in touch:
- Sandra Palacios (sandra.palaciosg at correo.buap.mx)
- Beat Estermann (beat.estermann at opendata.ch)
[1] As part of the CultureFLOW programme implemented in cooperation between BUAP and Opendata.ch in the context of the Swiss GLAMhack 2024.
#4thfloor
Pluralist Views on Artifacts in Ethnographic Collections
Approach artifacts in ethnographic collections through an artistic and/or participatory approach. To the extent possible, the projects involve and give the word to the communities concerned by the artifacts.
Pluralist Views on Artifacts in Ethnographic Collections
Artifacts in ethnographic collections are approached through an artistic and/or participatory approach. To the extent possible, they involve and give the word to the communities concerned by the artifacts.
Currently, student groups at Benemérita Universidad Autónoma de Puebla (BUAP)[1] are working on two such projects:
- “La Mujer Lipan” is a stop-motion/live-action short film project centering around a statue of a Lipan woman in the collection of the ethnographic museum in Geneva. It aims to dive into the collective memory of the Lipan people (the south-easternmost Apache tribe living across the border between Texas and Mexico). For this purpose, the project team is planning to travel to the border region in order to meet representatives of the tribe. In parallel, the museum has been approached with a request for cooperation.Video about the project, presented at the GLAM Night, on 5 September in Lucerne:
4.Mujer Lipan Presentación (EngSub).mp4
- The second project centers around Mexican masks in the exhibition of Museum Schloss Burgdorf (Burgdorf Castle Museum). The museum has suggested that the students produce a short video about objects in the museum’s exhibition giving their (the local, Mexican) perspective on it. The idea is to include the video in a video station in the museum, which will include other people’s perspectives on museum objects. The content of the video station will also be available on the web.
Video about the project, presented at the GLAM Night, on 5 September in Lucerne: 1.MexicanMasks.mp4
Further contributions may center around other artifacts or the topic may be approached on a meta level:
- How could / should such artistic and/or participatory projects around objects in ethnographic collections be documented and presented?
- To what extent would it make sense to present such projects and their outputs on a common webpage, thus creating another link between the museums, the artifacts, the artists, and the people concerned?
Participants:
Focus on Mexico:
- Sandra Palacios (BUAP)
- Beat Estermann (Opendata.ch)
- Various students’ groups at BUAP (approx. 25 persons).
Focus on Eastern Africa
- Sandra Becker (Wikimedia CH)
- Yara Schaub (Wikimedia CH)
Documentation:
GLAMhack 2024:
https://docs.google.com/presentation/d/1PcG10bAUCcD6dqs6rwyuRriiqWgYpGla77rH_WhSpaQ/edit?usp=sharing
[1] As part of the CultureFLOW programme implemented in cooperation between BUAP and Opendata.ch in the context of the Swiss GLAMhack 2024.
@4thfloor
Improved Access to Mesoamerican Collections Worldwide
Institutions holding artifacts from Mesoamerica are being approached in order to ask them to make their collections accessible online: their catalogs, photographs of the artifacts, etc. In line with the OpenGLAM Principles, they are asked to make their catalogs available in a machine-readable format, and – to the extent possible – to make the photographs available for reuse by uploading them to Wikimedia Commons. Progress of the project will be documented on Wikimedia Commons and/or on the Spanish Wikipedia.
Improved Access to Mesoamerican Collections Worldwide
Institutions holding artifacts from Mesoamerica are being approached in order to ask them to make their collections accessible online: their catalogs, photographs of the artifacts, etc. In line with the OpenGLAM Principles[1], they are asked to make their catalogs available in a machine-readable format, and – to the extent possible – to make the photographs available for reuse by uploading them to Wikimedia Commons. Progress of the project will be documented on Meta Wiki.
So far, this project has been pursued by Opendata.ch as a pilot project in cooperation with the Benemérita Universidad de Puebla (BUAP), focusing on ethnographic collections in Switzerland. In a next step, this project could be extended to Mexican institutions, before extending it to institutions in further countries. Reaching out to the different museums and convincing them to open up their collections requires a long-term outreach effort that is ideally coupled with a GLAM hackathon, a university class, or a Wikipedia edit-a-thon, in order to provide the institutions with concrete examples of data reuse. Ideally, a broader form of cooperation with the museums that goes beyond the mere publication of data evolves over time.
In the context of the Swiss GLAMhack, we are looking for Swiss partner institutions who are willing to support us in our endeavor.
To spur the creation of artistic projects based on Mexico-related heritage collections in Switzerland, Opendata.ch has teamed up with BUAP. Together, we have implemented a novel method (termed “CultureFLOW”) for the facilitation of artistic creative processes that engage with collective memories, in the form both of heritage artifacts and of living memories. A pilot project has been implemented that involves students in visual arts from Mexico as well as Mexico-related heritage collections in Switzerland. Three artistic projects that have arisen from this cooperation will be presented at the Open GLAM Night on 5 September 2024 in Lucerne.
As a next step, BUAP is planning to hold a GLAM hackathon in Puebla, México, in 2025, where the datasets / collections pertaining to Mesoamerican cultures will again be promoted and where their usage will be encouraged. Another avenue to facilitate the (re)use of these datasets / collections is the planned creation of a Wikipedia/Wikimedia Club at the university.
Making Collections Accessible Online: A Step-by-Step Guide
Making heritage collections accessible online is a step-by-step process (see figure 1). In this section, we summarize the insights gathered in the course of the Swiss pilot project in 2024, with a focus on ethnographic collections[2]. With regard to some aspects, earlier experiences with natural history collections are taken into account as well.
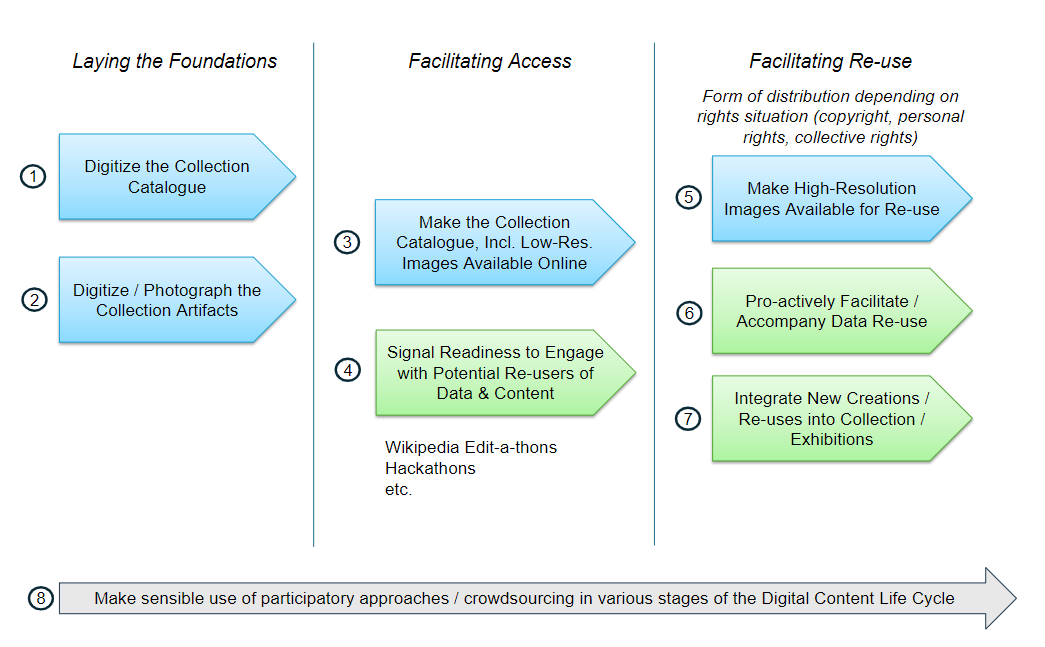
Figure 1: Making Collections Accessible Online in Three Phases
Phase 1: Laying the Foundations
There are two important first steps that need to be accomplished before collections can be made available online:
- Existing collection catalogs, finding aids, etc. need to be digitized. In some cases, a central collection catalog will need to be created from scratch, based on existing documents or the physical organization of the collection (no. 1 in the figure).
Best Practice:Digitize existing (analog) catalogs in order to be able to link the entries in the digital catalog to earlier versions of the catalog (sources). Example: Collection catalog of the Musée d’ethnographie de Genève (see the links to the historical catalogs at the bottom of the page).
- Given the fact that catalogs of ethnographic collections often contain only very little information about the artifacts and the information available may be of dubious quality, it is important to provide photographs of collection artifacts alongside the catalog information. Consequently, existing photographs need to be digitized or new photographs need to be taken (no. 2).
Best Practice:
When taking new photographs of artifacts, make sure to secure sufficient usage rights to the photographs to (later) be able to release the high-resolution images online under a free copyright license.(provide a sample contract…)
Phase 2: Facilitating Access
An important next step is to make the collection catalog available online (no. 3). Depending on the maturity level of the database, this can be done in various forms. As a rule, it is more useful to make the existing catalog available online now than to wait until it can be done in the perfect format .
Thus, for example, the publication of the catalog in PDF format as an intermediate solution (example: Inventory Lists of Museum der Kulturen Basel) provides for better online access than would the decision not to publish exports from the current collection database and to wait for the acquisition and roll-out of an online collection database instead.
Best Practices:
- Provide images alongside the text information contained in the collection database.
- The images should have the highest resolution (legally) possible, in order to maximize their usefulness.
- The entry for each artifact should have its own persistent identifier; persistent identifiers should be dereferenceable (i.e. an URI consisting of a standard path and the persistent identifier should return the description of the artifact in the online catalog).
- Artifacts should be findable in the collection database when a user enters the persistent identifier in the search interface.
- The landing page of the catalog should be referenced in Wikidata by means of a P8768 (online catalog URL) statement.
In addition, the institution should signal its readiness to respond to and to engage with potential re-users of the data. This can be done by different means, e.g.:
- Indicate an address and a method by which high-resolution images of collection artifacts can be obtained and ensure an efficient process for doing so.
- Advertise the catalog and digital images in the context of hackathons to encourage their re-use.
- Advertise the catalog, digital images, and further information about the collection in the context of a Wikipedia edit-a-thon.
Best Practices:
- Provide pointers to competent experts that can provide potential re-users of the data with additional information about the collection or individual artifacts.
Example Case: Musée d’ethnographie de Genève
Phase 3: Facilitating Re-use
Re-use of data and digitized artifacts can be facilitated using several strategies:
- If the rights situation (copyright, personal rights, collective rights of the communities concerned) allows for it, digitized artifacts should be made available online under a free copyright license in the highest quality possible. To facilitate their reuse in the context of Wikipedia and elsewhere, the high-resolution images can be uploaded to Wikimedia Commons, alongside their metadata.
Best Practices:
- To facilitate the interlinking of collections, collection items should be described on Wikidata. If no high-resolution image can be uploaded to Wikimedia Commons for legal reasons, Wikidata entries could point to the respective entry in the online catalog.
- If the detailed description of individual artifacts in Wikidata seems too onerous, object collections can be referenced by means of the method described at the WikiProject “Heritage Collections” in order to improve their discoverability in the future.
Example Case: Museum Rietberg…
- Data re-use can be proactively promoted and facilitated by an institution's active involvement in hackathons, edit-a-thons, or other participatory formats in the role of a data provider, challenge owner, and/or (co-)organizer, and/or by having its staff members participate actively in such events as resource persons, facilitators, or regular participants working alongside other participants.Example Case: Museum Schloss Burgdorf…
- To enhance their impact and visibility, third party contributions, such as new creations based on the data provided, improvements to the data, or linkages to other collections, can be fed back into the collection (or the collection database) and/or given some visibility within an institution’s exhibition(s).Example Case: Museum Schloss Burgdorf…
Make Sensible Use of Participatory / Crowdsourcing Approaches (All Phases)
Under development; cf. Oomen / Arroyo (2011): Crowdsourcing in the Cultural Heritage Domain: Opportunities and Challenges.
Example Cases (under development)
Museum Schloss Burgdorf
- Opendata.ch contacted the museum in early 2024
- …
From the Pilot Project to a Global Cooperation Project
The following approaches have been suggested to move from the pilot project to a global cooperation project:
- Roll the project out for other countries / geographical regions, adapting it to the local situation:
- Guatemala (as a part of Mesoamerica), via OKFN
- East Africa, via WMCH (currently in focus, as of Sept. 2024)
- Nepal (regional scope to be defined: e.g. India & Nepal), Open Knowledge Nepal
- India (regional scope to be defined: e.g. India & Nepal), partner organization to be defined / freelancer
- Ghana (regional scope to be defined), Open Knowledge Ghana
- Tanzania (regional scope to be defined), Open Knowledge Tanzania (in the process of being established)
- Finland (focus to be specified: incoming/outgoing), Avoin GLAM
- United Kingdom (focus: incoming; focusing on Mesoamerica in a first phase), Wikimedia UK
- Armenia (collaborate with Armenian ethnographic museums / Swiss institutions), Wikimedia Armenia
- Brazil - reach out to partners at the University of Sao Paulo (the university has its own ethnographic museum)
- Austria (focus: incoming; regional focus to be specified) - reach out to Wikimedia AT.
Research Question:
- What are possible models and the required framework conditions to roll out the project in another country / another geographical region?
Inputs / Ideas regarding further focus areas / cooperation partners in Switzerland
- Peru / Abegg-Stiftung (old textiles of Peru)Unfortunately there are almost no images of the special exhibition about old textiles of Peru on the website of the Abegg-Stiftung.
Here the archive page of the exhibition.
According to the press release, the textile are the property of the Abegg foundation, acquired by Werner Abegg between 1930 and 1933:
«Die frühperuanischen Textilien in der Abegg-Stiftung stammen fast alle aus der privaten Sammlung von Werner Abegg (1903–1984). Den grössten Teil davon erwarb er bereits am Anfang seiner Sammlungstätigkeit, zwischen 1930 und 1933.»
Exhibition catalogue: “Textilien aus dem alten Peru” (in German)Co-Produktion der Abegg-Stiftung und des Museums Rietberg, Zürich | 288 S., 250 Abb., 68 Zeichnungen, leinengeb., 23 x 31 cm, 2007, ISBN 978-3-905014-32-7
https://abegg-stiftung.ch/publikation/textilien/
- Focus also on access to scientific publications: The Open Access policies in the Global North have led to the establishment of funding models relying on Open Access Publication Charges which make it increasingly harder for researchers in the Global South to get papers published in established journals. The field of ethnographic studies could be used as one example field that is being analyzed from this point of view, with the perspective of improving the situation (alongside other fields, such as health, climate, etc.).Key cooperation partner: Budapest Open Access Initiative (in the process of being converted into an organization).
- Reference Research Expeditions on Wikidata to connect artifacts in different collections - see WikiProject Research Expeditions.
Contact:
- Sandra Palacios (sandra.palaciosg at correo.buap.mx)
- Beat Estermann (beat.estermann at opendata.ch)
Participants:
- Joris Burla (Museum Rietberg, Zürich)
- Sandra Becker (Wikimedia CH)
- Yara Schaub (Wikimedia CH)
- Flor Méchain (Wikimedia CH)
- Rose Mwikali
[1] https://openglam.org/principles/
[2] See also: Mexico-related ethnographic collections in Switzerland
@Lesesaal
Getting creative with Europeana
Create a project that leverages the Europeana Search API's new 'distance' search parameter for storytelling purposes. What shape this project takes is up to you: you can trace a single object or person throughout history on a map, you might create an app that allows users to search for objects close to their current physical location, or anything else that comes to mind. One great way to visualise your story is by using Humap: https://humap.me/
INTRODUCTION
Europeana is the European repository for digital cultural heritage, holding more than 50 million cultural heritage objects from more than 4000 institutions in Europe and beyond. Europeana's whole database is accessible for free using the Europeana API suite.
Europeana has been hard at work updating its Search and Record APIs and API documentation. Newly developed search features have opened up new possibilities for reuse of Europeana's database. One of those features is the geospatial search feature, which allows users to specify a point in space and search within a certain radius around that point. The Search API will return all objects in its database that fall within that search radius and conform to the other query parameters the user has entered. An example of this kind of search is:
More than 17 million Europeana objects are enriched with a latitude and longitude position in one or more of the following fields: currentLocation, coverageLocation or location. More information can be found here: https://europeana.atlassian.net/browse/EA-2996

an example of geographical storytelling: a screenshot of the Twin It! Humap website, which shows which 3D models each member state has submitted.
THE CHALLENGE
We at Europeana challenge you to create a project that in some way leverages the geospatial search feature for storytelling purposes. What shape this project takes is up to you: you can trace a single object or person throughout history on a map, you might create an app that allows users to search for objects close to their current physical location, or anything else that comes to mind.
Because this years' theme is 'On the Move', please think about a project that falls within those parameters. One audience group that loves engaging with cultural heritage in a geo-specific setting is tourists. If your project can solve an issue the tourism sector has (e.g. 'what are interesting places near me to visit?' or 'how can I know more about this thing I've just found?') using digital cultural heritage, you're appealing to a huge audience. An interesting subset of our collection to explore for glamhack24 is our Migration Collection. It consists of over 300K cultural heritage objects and can be accessed by using the query parameter 'theme=migration' in the Search API. example API call.
Are you looking for more inspiration on what content in Europeana you can reuse to appeal to the theme 'On the Move'? Then check out our stories tagged with 'migration': https://www.europeana.eu/en/stories?tags=migration
One of the ways you can nicely visualise your data is by using Humap.
GET IN TOUCH
You'll be supported during this challenge by Jolan Wuyts, API Outreach coordinator at Europeana, who can help you understand our APIs, curate API calls for you and generally be a mentor and expert on the Europeana database. The rest is up to you and the rest of the team!
***
Documentation details
You can find the docs for the europeana Search API here: https://europeana.atlassian.net/wiki/spaces/EF/pages/2385739812/Search+API+Documentation
Below is an extract from those docs detailing how to use the distance, location, CurrentLocation, CoverageLocation, and location sorting parameters:
We can filter results by distance using the function distance in the parameter qf. This example will look for objects with the words world war that are located (the object itself or the spatial topic of the resource) in a distance of 200 km to the point with latitude 47 and longitude 12.
Syntax: query=world+war&qf=distance(location,47,12,200)
https://api.europeana.eu/record/v2/search.json?query=world+war&qf=distance(location,47,12,200)
We can also use more specific fields instead of location: currentLocation (with coordinates from edm:currentLocation), and coverageLocation (with coordinates from dcterms:spatial and dc:coverage). For example, qf=distance(currentLocation,47,12,200) will filter the results to those located within 200 km of the coordinates indicated.
When we refine by distance (i.e., qf=distance(...)), we can also include distance+asc or distance+desc in the sorting parameter in order to rank the results by the distance to the coordinates.
Syntax: query=world+war&qf=distance(location,47,12,200)&sort=distance+asc
https://api.europeana.eu/record/v2/search.json?query=world+war&qf=distance(location,47,12,200)&sort=distance+asc
Refinement and sorting parameters can be concatenated. Each such parameter and the mandatory query parameter contributes a breadcrumb object if breadcrumbs are specified in the search profile.
more information about the specific content of fields like dcterms:spatial, edm:currentLocation and dc:coverage can be found here: https://europeana.atlassian.net/wiki/spaces/EF/pages/2106294284/edm+ProvidedCHO

Zentralgut, @4thfloor
GeoPhoto App
Develop a mobile application that displays georeferenced photos from the 'Glasplattensammlung Zug' to the user when they are in close proximity to the location where the photo was taken.
Code auf Github
Code: https://github.com/histify/geophotoradar Demo: http://photo.histify.app/
Stand am Freitagnachmittag:
Team: Lionel, Jonas, Kevin, Joel und Nadia
- Frontend: Das Frontend ist eine progressive Web Applikation (PAW). Das heisst, eine auf HTML und JavaScript basierte webseite-ähnliche Applikation welche Anfragen an das Backend übermittelt.
- Backend: Das Geo-Matching zwischen Standort des Benutzers und den Bildern wird mit einer Python Applikation bewerkstelligt. Für das Matching wird der Such-Algorithmus ElasticSearch verwendet. Die Kommunikation zwischen Front- und Backend erfolgt über eine FastAPI Schnittstelle.
- Inftrastruktur: Die Applikation läuft in einer Docker-Umgebung, d.h. es existieren für die verschieden Stages (Entwicklung, Test, Produktion) unabhängige Instanzen der Applikation.
- Versionskontrolle: Git
- Depdency Management: Poetry
- Datenfluss: User (PAW) -- (Standort) -- Backend (via Fast API).
1) Finde Bild: Backend (search-Query -- Datenbank.
2) Sende Bild an User: Backend -- (Bild) -- User
Challenge:
Eine Grosse Menschenmenge Auf Dem Postplatz. 1902. (https://n2t.net/ark:/63274/bz1wc85)
The history of glass plate photography dates back to the mid-19th century when it was introduced as a more durable and higher quality alternative to paper negatives. Coated with light-sensitive emulsions and exposed in cameras, glass plates produced detailed and sharp images, revolutionizing photography by allowing for greater precision and clarity. However, the process was labor-intensive and required careful handling of the fragile glass plates.
Glassplattensammlung Zug
The Bibliothek Zug houses over 3600 of these plates, known as the "Glasplattensammlung Zug." This collection captures a diverse array of scenes, including architectural landmarks, scenic landscapes, and everyday life moments. Due to the fragility of these glass plates and their archival confinement, presenting these captivating photographs to the public was a significant challenge in the past. Utilizing advanced digitization techniques, the Bibliothek Zug partnered with Memoriav to digitize the collection and georeference approximately 2500 photographs from the late 19th century to the 1950s. About half of these images were taken in the Canton of Zug, with a notable concentration in and around the city of Zug.
Challenge
With the photos accessible on the Zentralgut website, the Bibliothek Zug aims to bring the collection to a broader audience through the development of a mobile app. This app will notify users when they are near a location where one of the georeferenced photos from the "Glasplattensammlung Zug" was taken, offering a unique and immersive way to explore the region's history. This app provides a look into the past, allowing users to compare historical life and architecture with the present-day, offering a distinctive perspective on Zug's evolution over time.
Screenshots
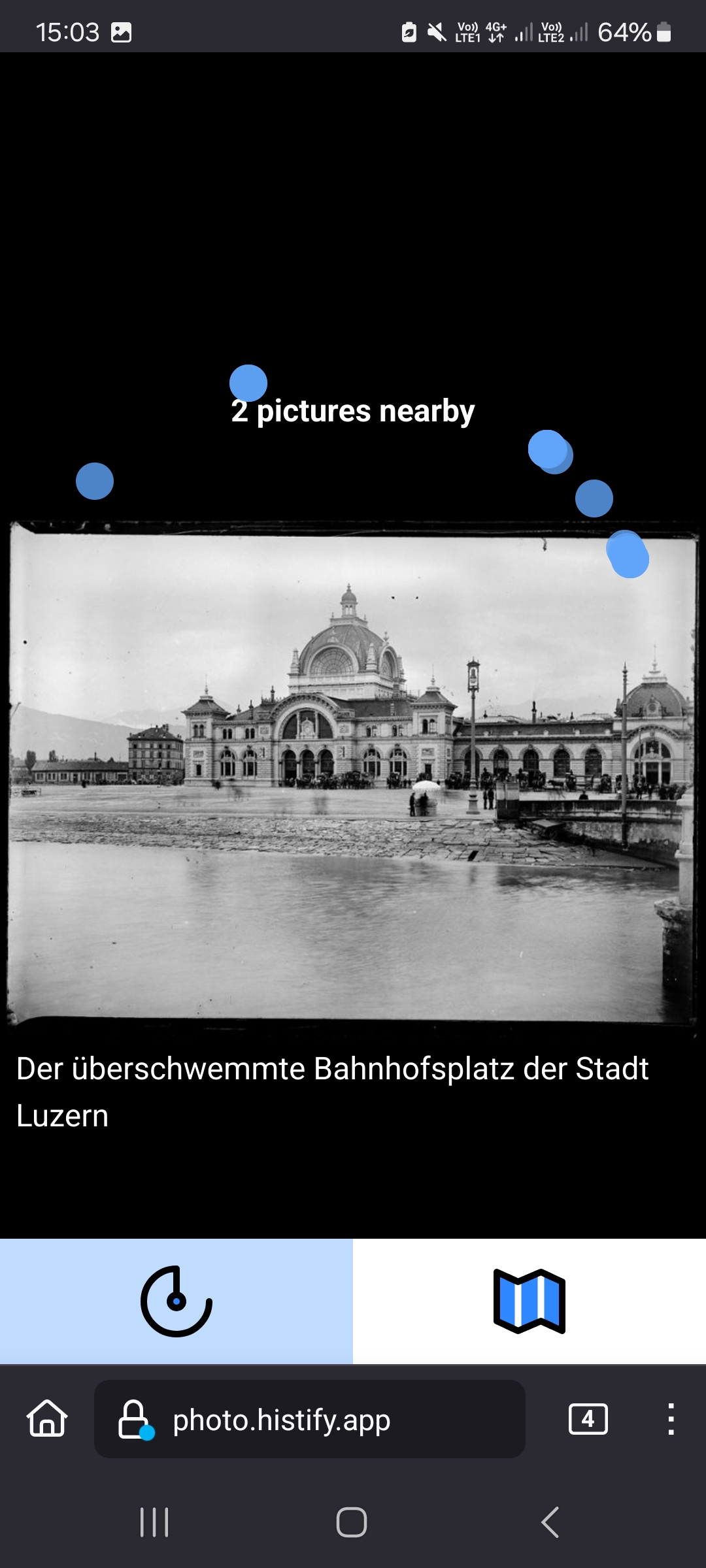
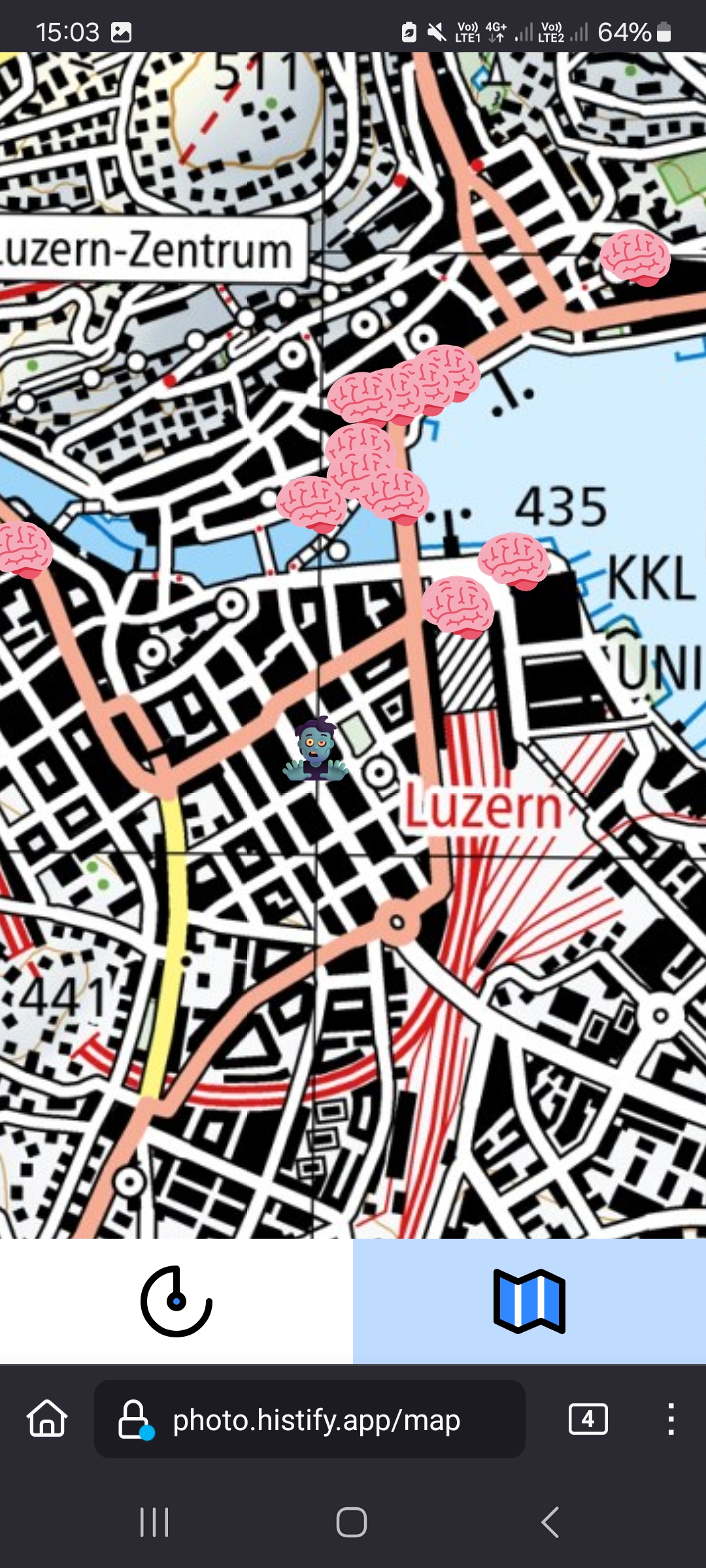
fixed!
Micro-Bug-Fix Task-Force
Bonus room to triage GLAM bugs and fix
Tired of designing and implementing mind-blowing prototypes that... you'll archive in the "side-projects pile" in two days? 🫠You unlocked this bonus room where you can jump in and out anytime. A parallel help-desk dedicated to troubleshooting random super-tiny bugs in various horizontal Free/Libre Open Source projects. Just because we can try!
Project workflow: sit down > take a pickaxe > dig into your software backlog > explain one bug > reproduce > troubleshoot > propose a solution > discuss the solution > propose a patch > share the patch > test the patch > and get the best of the prizes: the satisfaction of having fixed another bug in our planet.
At the end of the event, some awards will be given to celebrate the bug-fixes under the category "maximum effort, minimum result" 🤩
P.S. We cannot share a list of bugs right now because we do not know what is coming from you.
https://etherpad.wikimedia.org/p/MicroBugFixTaskForceGLAMhack2024
@4thfloor
Self-organized Art Initiatives in Switzerland
Data set with self-organized art initiatives in Switzerland
The research project “Off OffOff Of?” (2015-2019) undertook an analysis of self-organized art spaces in Switzerland. It has thus created a unique overview of an important part of contemporary Swiss cultural life. An important basis for the scientific work and the cultural policy discussion was the compilation of a data set with over 700 of such initiatives. This data set is accessible via the interface of the project website https://selbstorganisation-in-der-kunst.ch. However, no further use has been made to date. The challenge aims to make the dataset more accessible, i.e. above all to link it to Wikidata and to store parts of it in Wikidata.
- Dataset: https://github.com/birk/swiss-art-initiatives
- Case study documented on https://meta.wikimedia.org/wiki/Open_Science_for_Arts,_Design_and_Music/Case_studies/Mapping_Self-Organization_in_the_Arts
- Wikidata item for the project: https://www.wikidata.org/wiki/Q129406103
- Notes of the working group: https://etherpad.wikimedia.org/p/artinitiatives
- Slides of the presentation https://commons.wikimedia.org/wiki/File:Slides_of_Self-organised_art_initiatives_in_Switzerland_-_challenge_10_at_GLAMHack_2024.pdf
In the image a screenshot of the interactive map of the self-organized art initiatives in Switzerland
https://selbstorganisation-in-der-kunst.ch
Self-organized Art Initiatives in Switzerland
This data set was created as part of the "Off OffOff Of?" research project at the Lucerne School of Design, Film and Art. It contains information about more than 700 self-organized art initiatives in Switzerland and is the basis for the project website selbstorganisation-in-der-kunst.ch.
The data set consist of 3 tables, where data/projects.csv is the main table and data/people.csv and data/places.csv refer to it with additional information. datapackage.json explains the structure and the data types according to Frictionless Data conventions.
The data set has been cleaned up and ingested into Wikidata during GLAMhack24.
![]()
![]()
Processing steps
- Geocoordinates (WGS84) have been added to
data/places.csvviascripts/retrieve_WGS84.pyusing the Nominatim API. - Data has been cleaned and adapted for Wikidata using OpenRefine.
- Reconciled against Wikidata, Q-numbers have been added to the data sets.
Wikidata
Parts of the data have been ingested to Wikidata. The ingested self-organized art initiatives are identified as described by source (P1343) Unabhängig, prekär, professionell (Q130250557), the main publication of the research project.
The following queries can be used to retrieve the data.
Simple list of all initiatives:
SELECT ?item ?itemLabel WHERE
{
?item wdt:P1343 wd:Q130250557.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
Example of a list with additional information:
SELECT ?item ?itemLabel ?placeLabel ?start ?end WHERE
{
?item wdt:P1343 wd:Q130250557.
OPTIONAL {
?item wdt:P276 ?place.
}
OPTIONAL {
?item wdt:P571 ?start.
}
OPTIONAL {
?item wdt:P576 ?end.
}
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
World map of self-organized art initiatives:
#defaultView:Map
SELECT DISTINCT ?project ?projectLabel ?geo WHERE {
{ ?project wdt:P31 wd:Q3325736. }
UNION
{ ?project wdt:P31 wd:Q4034417. }
# ?project wdt:P17 wd:Q39. # Switzerland only
?project wdt:P625 ?geo.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
License
The content of the research project "Off OffOff Of?" is released under the license CC BY 4.0, unless differently stated; the structured data about the self-organized art initiatives are released with the license CC0 1.0.
@Basement
Pimp my portrait gallery
During the GLAMhack23 a prototype of an virtual exhibition of the portrait gallery of "Merkwürdige Luzernerinnen und Luzerner" in the library hall of ZHB Lucerne was produced. Let's continue the process
Visualize Lucerne Portrait Gallery
Demo: https://zhbluzern.gitlab.io/visualize_portrait_gallery/src
Description
Gallery of remarkable people of Lucerne
In the library hall of the ZHB Lucerne you find 260 painted portraits (oil on canvas) owned by the "Korporation Luzern" about remarkable persons of the history of Lucerne (the so called "merkwürdige Luzernerinnen und Luzerner") The portraits are digitized and open access available via ZentralGut.ch, the repository for the digital cultural heritage of Central Switzerland hosted by ZHB Lucerne. 240 portraits are already available under public domain, 21 portraits are still under copyright and only available at ZentralGut.
Biographies about the "merkwürdige Luzerner:innen"
Along the portraits the library has a collection of short biographical notes about each portraited person. The so called "Kurze Lebens-Notizen zu der Portrait-Gallerie merkwürdiger Luzerner auf der Bürgerbibliothek in Luzern" are digital available at ZentralGut(https://n2t.net/ark:/63274/zhb1309s) but furthermore we made a double-checked fulltext transcript using WikiSource as crowdsourcing platform. These corrected biographical notes are stored also in the portraits metadata at ZentralGut and made the portraits a little bit more retrievable.
Wikidata-fication of the potrait gallery
Every portraited person has already its own Wikidata-Item. These items has different statements, according to the data already stated in wikidata or available using different sources, starting with the short biographical notes. The following Query returns all biographical items, with image and URL into the Wikisource transcript of the biographical note.
Portraits uploaded to Wikimedia Commons
The 240 portraits under public domain are already uploaded to Wikimedia Commons and linked to the wikidata item of the described person, unless there was already a satisfied image stated. The addition or exchange of images in different Wikipedias is a currently ongoing task (2023-09).
Challenges
ZHB Luzern provides a more or less fully "wikified" dataset of biographical information, a digitized biographical source, interoperable and linked biographical items and decent portaits of the so-called remarkable people from Lucerne. According to the different statements avaialble in Wikidata a lot of different queries could be build and those group of people therefore analyzed. E.g. search for relative, people became the same political position, member of the same religious order enz.
- Buidling a variety of analysis (and visualisations) on the biographical informations of the portraited persons
- Add more granular information about differnet people (e.g. political parties, religion, relatives) or links to external sources
- Think about a (3-d) virtual visualization of the library hall and its portrait gallery.
Links
@Basement
Perceptual Plausibility
Build a game for classifying images as plausible (human-created) or implausible (machine-generated), that could also be "played" by an autonomous agent in order to automatically discern the provenance of content in a GLAM context, such as the images or other content shared on Wikimedia Commons. Make sure to include both the metadata (such as the Wikidata record) as well as the actual content in the assessment. A collection of synthetic and actual images from a Swiss municipality will be provided for this challenge.
To support investigation into the provenance of open cultural content, our challenge was to gamify data collection in Wikimedia - in particular, to decide the extent (e.g. a non-binary rating) to which an image is synthetic or generative in origin. The idea was to build on prior work like the Depiction Wikidata Game, which asks users to "Decide whether the image depicts the named item", or not. See Challenge Notes below for further details.
GLAMhack 2024 Project
We started with brainstorming options, developing a sensible mission statement, and planning the work in Excalidraw:

In the shared Etherpad we are collecting links to tools and resources.

Using a slightly adapted version of the WHY-NOW-HOW matrix, our features were quickly prioritized.
Pen and paper usually works best for nailing down a sketch (we went through a few iterations ..) with a vision that we can commit to.
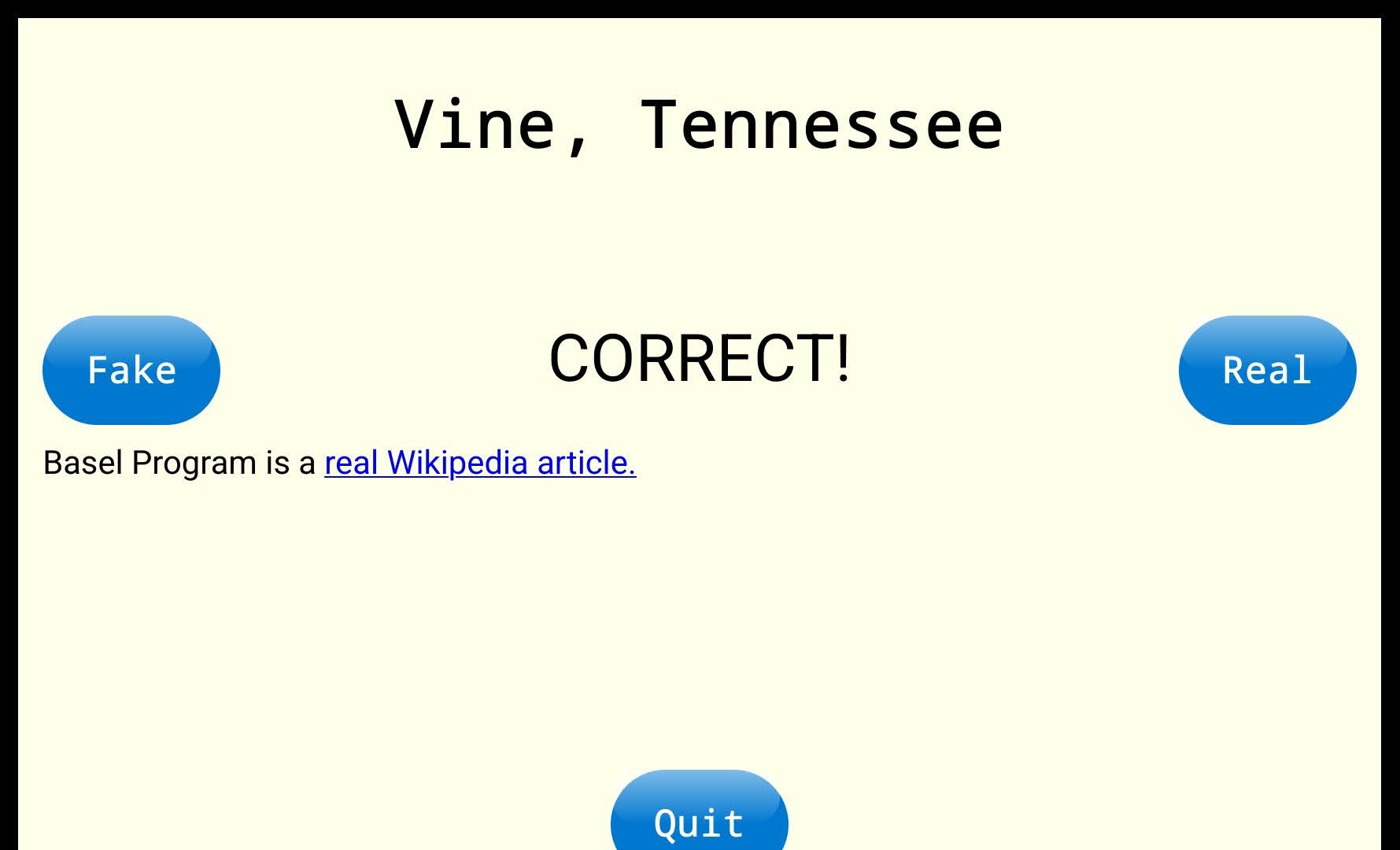
We discovered WikiGuess by ComputerCow: a simple yet delightful game about guessing real/fake Wikipedia titles that helped us to test out our concept.
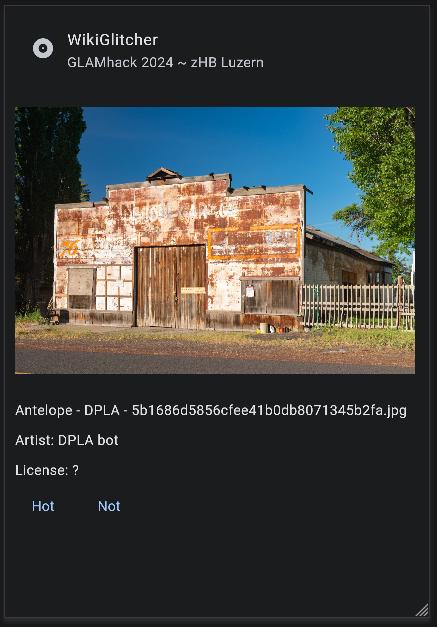
Then we set up a Flet/Python app open source project to flesh this out a bit more, and shared this in GitHub. More screenshots are in presentation slides and details of how to run it are in the README section below. Due to an open bug we have not yet been able to publish the prototype.
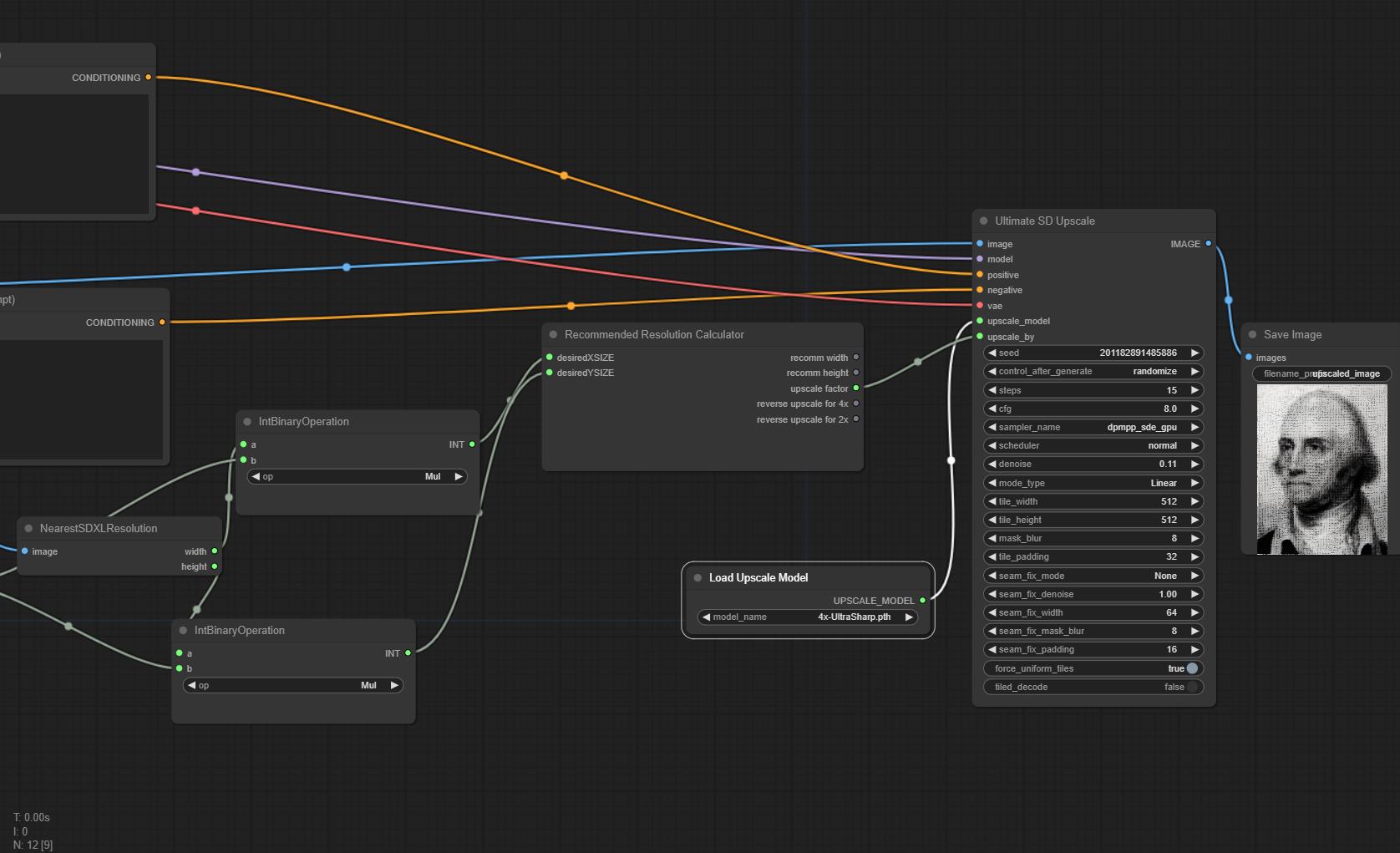
In parallel, we looked into how an AI evaluation or enhancement could be plugged into our app. Selecting several open source machine learning models, and testing them in the ComfyUI framework, we were able to demonstrate the potential of these techniques. Our model parameters are shared in this Switch drive folder. The workflow was deployed on Replicate, but we did not have time to connect the API.
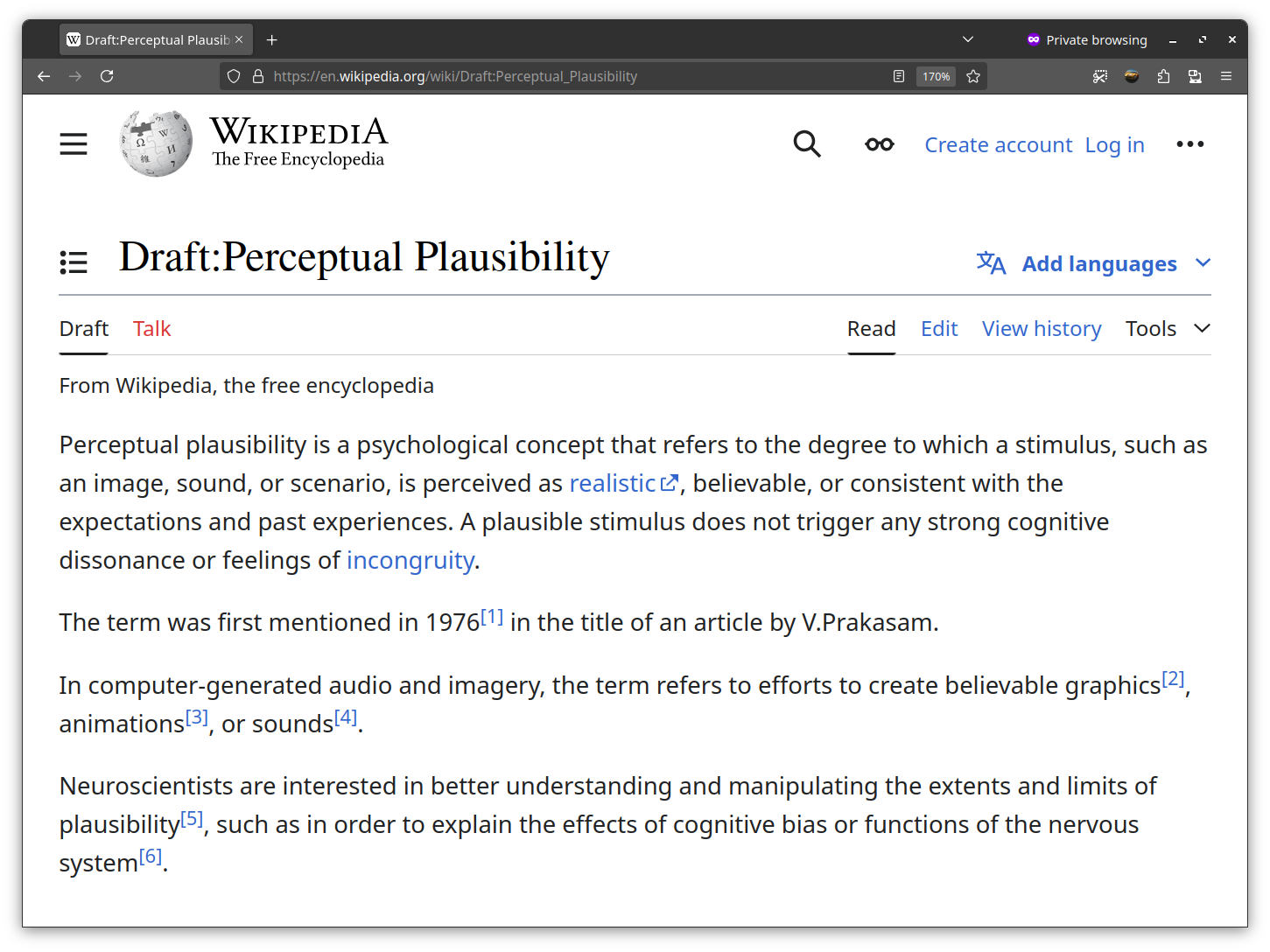
Finally, a Wikipedia article on the topic of our challenge "Perceptual Plausibility" has been drafted, and we came up with the name Wiglitcher for our app (a portmanteau of Wiki and Glitch). A link on neuropsychological research on the topic "Reality Bending" may lead you to more interesting exploration of the topic!
Thanks to absolutely everyone at the hackathon, especially to the Pimp my portrait gallery team at the next table for their valuable support and collaboration.
Challenge Notes
As a dataset for this project, we propose to compile and curate additional media from artists in the municipality of Köniz, where a culture festival is being run in parallel to this year's GLAMhack. In addition to the 100+ existing Wikimedia Commons entries we can source additional materials to upload. We can then generate an equal amount of images using Stable Diffusion (with Community License) close to the subject matter of the Commons collection. Some of these images will be "uncanny", making it hard to decide their origins. The complete collection will be provided as a Data Package in open formats. A game could be prototyped with an open source framework used for citizen science (e.g. PyBossa) and inspired by other crowdsourcing projects (e.g. StreetComplete).
The output of this challenge should be a concept sketch, a prototype, or even playable game, that can engage the public and contribute to the debate on Perceptual Plausibility outlined below.

Screenshot of the Depiction Wikidata game, Sigalov and Nachmias 2023
The GLAM community is at the heart of academic and critical debate on the use of machine learning (ML) in creative domains. Whether generating text, images, sounds, video, or 3D metaverses, we explore the multimedia advances and augmentative potential of artificial intelligence (AI) with active interest and critical reflection on the impact to society.
With ML and AI now built into illustration tools, photocameras, and other recording devices, it may be argued that the lines of what is or what is not "generative" are indeed increasingly blurry. One aspect of this discussion that we might agree on as designers or critics alike, is that Perceptual Plausibility - such as photo-realism, in the case of images - is an important differentiating factor. See the History of Text-to-image models and Uncanny Valley for further references on Wikipedia.
There are numerous tools and even ML-based benchmarks to test the generative provenance of uploaded content, with varying levels of accuracy and applicability. We even see increasing use of adversarial techniques like Nightshade. The Turing test begs the question of whether determining plausibility (realism) as a human observer or moderator will be possible for much longer. See also: Stable Diffusion and Why It Matters and Evaluating Diffusion Models.
Here is an excerpt of the recently posted official guidance on Commons:AI-generated media states:
Per the Commons project scope, only media that are realistically useful for an educational purpose should be hosted on Commons. Just because an AI image is interesting, pretty, or looks like a work of art, that doesn't mean that it is necessarily within the scope of Commons. While some AI-generated media fall within our scope, media that lack a realistic educational use may be nominated for deletion.
The legal discussion, a confusing cornucopia of legislative debates on AI and copyright around the world related to this, was neatly summed up last October by Creative Commons in Understanding CC Licenses and Generative AI:
We encourage the use of CC0 for those works that do not involve a significant degree of human creativity, to clarify the intellectual property status of the work and to ensure the public domain grows and thrives. ... Neither copyright nor CC licenses can or should address all of the ways that AI might impact people. There are no easy solutions, but it is clear we need to step outside of copyright to work together on governance, regulatory frameworks, societal norms, and many other mechanisms to enable us to harness AI technologies and practices for good.
In terms of content labelling, there have been several initiatives in this community:
- How should AI-generated media be handled? section of the Guidance mentioned above;
- Category:AI-generated images by Commons users;
- Wikimedia Commons AI/Essay, part of a rejected Proposal for a sister project (similar to WikiAI);
- AI Sauna/AI for Wikimedia Commons at a recent community event;
Recently the Vimeo video sharing platform, an early adopter of CC licenses, announced new AI guidelines, along with a revised Terms of Service.
Image: Vimeo Help Center
A project like this one could also be used to explore critical questions about the way online gigs and microtasking is used for building AI datasets: see Inside the AI Factory, and Are CAPTCHAs used to to train AI?

This image, and the one in the header, were rendered using Stable DIffusion XL 1.0.
Please feel free to leave a Comment here with any further links.
Wiglitcher App
For GLAMhack 2024..
To run the app:
Create a .env file and put the Personal key that you made on Wikimedia API in there like this:
WIKIMEDIA_TOKEN=eyJ0eXAiOiJKV1QiLCJ...
Then you can:
flet run [app_directory]
@Lesesaal
Unveiling the Secrets of Zurich’s Nightly Visitors (1780-1818)
The Zentralbibliothek Zürich has digitized a collection of historical documents known as the "Zürcher Nachtzedel," spanning from 1780 to 1818. These nightly registers, meticulously recorded by the town’s "Nachtschreiber," capture the names of visitors staying in Zürich’s inns each evening, offering a fascinating glimpse into the past. Notable figures such as Goethe and Hölderlin are among those whose stays in Zürich are documented, making this collection an invaluable resource for historians, researchers, and enthusiasts alike. However, this rich data is currently locked in image format, without machine-readable text (OCR). To unlock its potential, we need your help!



Your Mission:
Join us in transforming this historical data into a valuable, searchable resource by applying OCR technology and verifying the results. Once we have high-quality text, we can visualize and analyze the data to uncover who stayed in Zürich and how often, revealing patterns of social interaction and stratification.
What We're Looking For:
- OCR Experts: We need 2-3 participants with experience in OCR software to extract text from the digitized images with accuracy.
- Data Verifiers: We need several meticulous individuals to review the OCR-generated text, ensuring it correctly identifies names, dates, and locations. Your task will be to verify and correct any errors, ensuring the data's integrity.
- Named Entity Recognition and Linking Specialists: We want to automatically differentiate between persons, locations and possibly occupations-entities and link as many as possible to authority resources like Wikidata. Can you help us with best practices scripts or AI-prompts?
- Data Visualizers: Help us visualize the history of nightly visitors to Zürich: At what time did people from what places visit Zürich?
Why Participate?
- Contribute to History: Your work will help make this unique dataset accessible to researchers worldwide, shedding new light on Zürich’s historical visitors.
- Sharpen Your Skills: Whether in OCR technology, data verification, named entity recognition and linking, or historical research, this challenge offers a chance to hone your expertise in a meaningful project.
- Collaborate and Network: Work alongside passionate individuals, share knowledge, and make connections that could last beyond the hackathon.
Join us in this exciting challenge to bring Zürich's past to life and make history accessible to all!
Link to Github-Repo:
If you want to handle the images, this repo might be helpful...
https://github.com/NbtKmy/nachtzeddel
Link to our data set:
Challenge 14 "Unveiling the Secrets of Zurich’s Nightly Visitors (1780-1818)" /GLAMhack 2024
This Repo contains the JPG-images from Zürcher Nachtzedel (1780-1784) and an OCR example with Claude 3.5 on Colaboratory.
Contents
- "ideas" folder contains;
- Python-Notebook for OCR with Claude 3.5
- OCR results in txt format (in the folder "ocr_mit_claude")
- Text contents in TEI/XML format (in the folder "tei_beispiele")
- "images" folder contains;
- images from Zürcher Nachtzedel (1780-1784). The images here are not in the orginal format
- images with odd number are removed, because they are the rear sides of the flyers which have no addtional information
@Lesesaal
Unraveling Zürich’s social and family networks in Keller-Escher's "Promptuarium"
GLAMhack2024 project for creating family relations graph
The "Promptuarium genealogicum" by Carl Keller-Escher is a monumental work, spanning 2,800 pages and detailing the genealogies of 258 historic families from Zürich, with roots tracing back to the 16th century. Thanks to a dedicated Citizen Science project conducted by the Zentralbibliothek Zürich, this vast trove of genealogical information has been meticulously transcribed, offering a valuableresource for anyone interested in Zürich’s historical families and their social histories. However, while the data has been transcribed and organized, there’s a challenge ahead: connecting these historical records with modern biographical databases and visualizing the intricate relationships within these families. We need your expertise to bring these connections to life!
Your Mission:
Dive into Keller-Escher’s genealogical data and help identify and connect the individuals recorded in this work to biographical databases like VIAF, GND, and others. Then, take these connections and create Linked Open Data (LOD) to visualize the complex web of relationships that bind Zürich’s historic families together.
What We're Looking For:
- Prompt Engineers and coders: Using artificial intelligence, we will try to extract and structure data describing persons mentioned in the transcribed data. To this end, your task will be to find prompts for the AI to structure the data as best as possible. Some experience with ChatGPT is all you need to help.
- Historical Detectives: We need participants with a knack for research and a passion for history to identify the individuals in Keller-Escher’s work. You’ll search for biographical data from various sources, such as VIAF and GND, and match these with the names recorded in the genealogy.
- Data Integrators & Creators: Once the historical detectives have identified the persons, we need participants skilled in data modeling and creation to produce Linked Open Data (LOD). Your task will be to create and structure the data, linking these individuals and their relationships in a way that can be easily visualized and explored.
- Visualization Experts: Help us transform the structured genealogical data into engaging visualizations. By mapping out relationships and family trees, you'll make it easier for researchers and the public to explore the rich genealogical and social history of Zürich.
Why Participate?
- Bring History to Life: Contribute to creating a living, interconnected web of Zürich’s past, making it accessible and understandable to everyone.
- Learn and Innovate: Gain hands-on experience with historical data, Linked Open Data (LOD), and advanced visualization techniques, all while working on a meaningful project.
- Collaborate and Connect: Work alongside a passionate team of historians, data scientists, and visualization experts, building connections that could lead to future opportunities.
Join us in this challenge to illuminate Zürich’s genealogical and social history and create tools that help exploring the past!
Link to our data set:
https://opendata.swiss/de/dataset/promptuarium-genealogicum-des-carl-keller-escher
Etherpad:
https://etherpad.wikimedia.org/p/GLAMhack24\_Keller-Escher
Documentation
Test Family Graph
python -m unittest test_module.TestClass.test_method
````
# Create environment with conda/mamba
````
mamba create -y -n carl-escher-prompt python=3.11
mamba activate carl-escher-prompt
mamba install -y --file requirements.txt
````
# Visualization
Go to: https://gephi.org/gephi-lite/
And load file: data/graph_data/graph_with_styling.gefx@4thfloor
Randomly Wandering Around
Find the locations of various old photos and paintings in Lucerne
- Final Project (please open it on a mobile phone in lucerne)
- Figma Prototype:
Initial Pitch
Exploring a city without following a map can be fun. That's why we want to build an experience where users have to find the locations of various old photos and paintings in Lucerne.
🕹️ User Journey / Gameplay Loop
Note: The screens are just to illustrate what we're currently imagining, not to look pretty. :) Also, this is just the idea as of right now, but could still change a lot.
First, the user sees an overview with all spots to discover. Each spot shows how far away it is from the users real life location:

When they get close to a spot, they can take a picture:


They should try to match the original image's perspective as closely as possible:

Then, they can read about the spot and the context the image was taken/painted in:

🌻 Team
We're currently two people:
- Lea, Student (Design/UX)
- Dorian, Student (Programming)
We're very open to working with more people. It would be especially nice to find someone who's interested in finding good pictures and paintings and write something about them. But more designers and programmers are also very welcome, of course. :)
🧑💻 Implementation
We would implement the project as a website, because the Geolocation API and MediaDevices API are good enough.
Audio2Commons (tbc)
Project by Sandra Becker, MEG

{kind=link}
{kind=link}